
Как собрать платформу обработки данных "своими руками"?
Большое количество российских компаний столкнулись с ограничениями в области ПО. Они теперь не имеют возможности использовать многие важные инструменты для работы с данными. Но, как говорится, одна дверь закрылась — другая открылась. Альтернатива зарубежным решениям есть: платформу обработки данных можно создать своими силами. Расскажем, как мы в ITSumma это сделали, какие компоненты использовали, с какими ограничениями столкнулись и зачем вообще всё это нужно.
Предыстория (очень короткая)
Один заказчик, который заинтересовался нашими компетенциям в построении инфраструктур, предложил крупный интеграционный проект. Архитекторы клиента придумали сложную и большую платформу, которая включала в себя машинное обучение, обработку данных и управлялась с помощью Kubernetes. Нам поставили задачу реализовать проект платформы, настроить связность элементов, построить и запустить инфраструктуру в эксплуатацию.
В итоге всё прошло хорошо и заказчик доволен. А у нас возникла идея скомпоновать свою платформу — такую, чтобы она была доступной не только большому бизнесу, но и компаниям среднего и малого масштаба. То есть сделать так, чтобы можно было получать большие возможности и не платить при этом огромные деньги.
Из чего состоит наша платформа ITS DPP
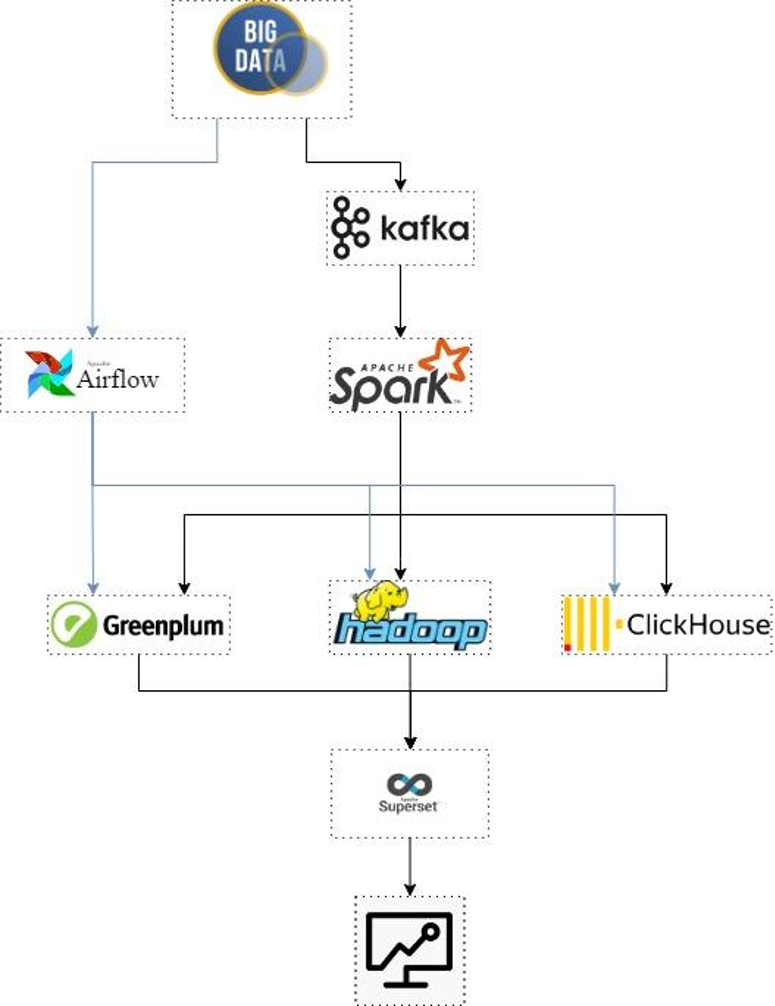
Все компоненты собраны в схему, которая позволяет запустить платформу на двух-трех серверах. Разумеется, мы используем только ПО с открытым исходным кодом — найти на рынке специалистов для его обслуживания не составляет труда.
Итак, вот из чего состоит платформа в текущем виде.
Блок 1 — Первичное получение данных
Для сбора данных из источников мы используем Apache NiFi и Debezium, для постановки их в очередь обработки — Apache Kafka.
Основные задачи:
-
собирать сырые данные из всех подключенных источников;
-
не терять их при передаче на обработку;
-
оценивать объемы получаемых данных;
-
рассчитывать требуемые ресурсы для их обработки и хранения.
Блок 2 — Обработка данных
Для пакетной обработки используем Apache Airflow, для потоковой — Apache Spark.
Основная задача блока — подготовить данные для аналитики. То есть из сырых данных сделать такие, на основе которых можно строить запросы, графики и отвечать на самые важные для бизнеса вопросы.
Блок 3 — Хранение данных и аналитика
У данного блока список задач весьма разнообразен — таков же, в соответствии с этим, и набор компонентов.
Основные задачи блока:
-
хранение сырых данных — Apache Hadoop;
-
хранение обработанных данных — Greenplum;
-
обеспечение выполнения запросов на основе данных — Greenplum;
-
аналитика данных (создание отчётов и дашбордов на основе готовых запросов) — Apache Superset;
-
сбор витрин данных (позволяет увидеть срез по данным) — Apache Airflow, ClickHouse.
Блок 4 — Инфраструктурное обеспечение платформы
Основные задачи блока:
-
обеспечение IaC, т.е. контроль и обновление конфигураций компонентов платформы — Ansible, Nexus;
-
обеспечение CI/CD процессов, т.е. поддержание полного цикла, от разработки и хранения кода до доставки его на прод — Gitlab, Jenkins;
-
мониторинг состояния компонентов, их связей и процессов платформы — встроенная система мониторинга, собственные экспортеры для Prometheus.
Как всё работает
Сбор данных
Этот процесс реализован с помощью пул/пуш-моделей. Для него важны следующие характеристики:
● регулярность — как часто поступают данные;
● объемы поступающих данных;
● объемы пакетов с этим данными.
Соединение с внешними источниками данных происходит помощью Apache NiFi. Для промежуточного хранения данных на платформе есть шина — Apache Kafka, куда направляются все потоки данных. Там они находятся в очереди до тех пор, пока ими не займется обработчик, который отправит их куда нужно.
Модели получения данных из источников по компонентам распределены следующим образом:
● Apache Airflow “подтягивает” данные из источников, используя пул-модель (от английского глагола to pull — тянуть), и предает их напрямую в озеро данных. Этот подход мы используем на платформе для батчинга — пакетной передачи данных.
● Apache Kafka и Apache Spark используют пуш-модель (от английского to push — толкать). При этом Apache Nifi собирает данные из внешних источников и передает продюсерам Kafka, выступающим в качестве шины данных. Дальше поток идет на Spark и потом записывается в хранилище для дальнейшего использования. Так на нашей платформе работает стриминг — извлечение, обработка и запись данных в реальном времени.
Отдельно стоит упомянуть Debezium, который работает по принципу CDC — Change Data Capture — и может использовать обе модели, пул и пуш. Такой подход ускоряет потоковую передачу и обработку за счет того, что не приходится “таскать” существующую базу данных в модуль промежуточного хранения целиком. CDC подключается к базе, регистрирует изменения в ней, собирает только измененные поля и отправляет в шину данных. Дальше все работает как пуш-модель.
Обработка данных
Платформа использует оба принципа обработки данных — ETL и ELT. Потоковая обработка у нас проходит на Apache Spark, пайплайн обработки данных реализуем при помощи Spark Job. Для пакетной обработки используем Airflow, пайплайн для нее делаем через DAG-файлы.
Хранение данных
Хранятся данные в двух сущностях:
- Озеро данных (Data Lake), сделанное на Apache Hadoop.
- Data Warehouse — это хранилище данных, сделанное на Greenplum. Greenplum — кластеризуемое решение, основанное на свободной объектно-реляционной СУБД PostgreSQL. Это значит, что хранилище может без потери производительности вертикально кластеризовать сколько угодно. А стало быть, в перспективе — хранить огромные объемы структурированных данных.
Визуализация данных
Основной инструмент визуализации — Apache Superset, с его помощью можно делать графики и дашборды. Но проблема дашбордов во множестве взаимосвязей внутри базы данных, что существенно снижает скорость выполнения сложных запросов и вывода информации. Поэтому мы добавили на платформу возможность создавать витрины данных.
Для большого объёма данных мы рекомендуем использовать ClickHouse. Например, если у вас крупный бизнес со множеством источников данных, которые необходимо обрабатывать и быстро готовить к аналитике. Но в стандартной конфигурации платформы с подготовкой таблиц для визуализации прекрасно справляется Greenplum.
Сложности при внедрении
Были и шишки, и камни, и грабли. Несколько советов, как вам на всё это не наступить.
Зафиксируйте версии компонентов
Совместимость версий может доставить вам достаточно проблем. Поэтому советуем найти такие версии компонентов, которые совместимы друг с другом, и постараться их не менять.
Следите за обновлениями версий
После обновления может потеряться обратная совместимость. Поэтому если обновлять версии — то всё вместе.
Будьте готовы к тому, что придётся что-то дорабатывать
У нас на платформе не работала нативная связь между компонентами — Apache Spark и Greenplum. Чтобы они корректно взаимодействовали, нам пришлось написать кастомные коннекторы для них.
Этот опыт описан в нашей статье на Хабр. А само решение можно забрать с GitHub.
Учитывайте важность автоматического масштабирования
Для примера возьмём интернет-магазин, который расширил линейку товаров. Данных стало приходить гораздо больше, потому что число клиентов на сайте увеличилось. Справляться с обработкой данных стало сложнее — у серверов не хватает вычислительных мощностей. Необходимо масштабирование.
Но масштабироваться при увеличении нагрузки нужно быстро, поэтому автомасштабирование в этом случае выходит на первый план.
Мы решили эту проблему, проводя развертывание с помощью Ansible и Terraform. Операция шаблонная: достаточно разобраться один раз, и вопрос её тиражируемости на платформе будет решен.
Заключение
Нашей целью было сделать доступными для малого и среднего бизнеса сложные системы, которые работают с данными — как, например, у Газпрома. Выполнить эту задачу удалось с помощью определённого упрощения состава платформы и автоматизации части процессов.
Обычно небольшие компании используют для аналитики что-то подобное Google Cloud Platform и Google Analytics. При этом приходится платить за возможность подключить свои источники данных, облако; к тому же этим инструментам часто не хватает гибкости, чтобы соответствовать конкретным запросам бизнеса.
Мы создали решение, которое обладает типовой архитектурой и оптимизировано для работы с задачами малого и среднего бизнеса. При этом оно позволяет пользователям платформы консолидировать большое количество разнородных источников данных, их обработку и структуризацию, поиск инсайтов для развития или увеличения прибыли.
И всё это в открытом доступе: опробовать платформу аналитики и обработки данных ITS DPP в демонстрационном режиме можно по ссылке.





