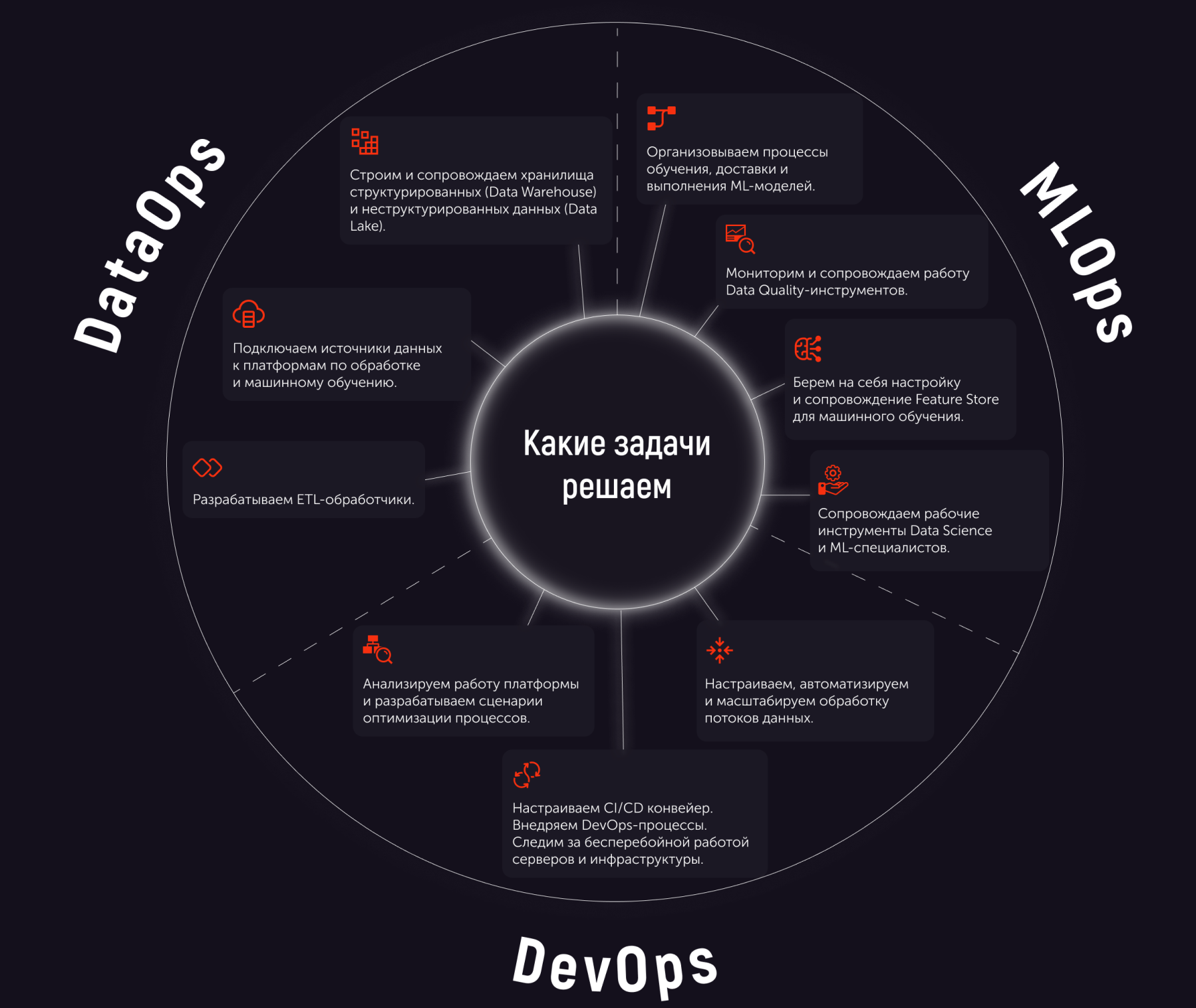
Куда приводят Ops'ы: современный ландшафт *Ops-специализаций
Манифест DevOps вышел уже больше десяти лет назад. Но времена меняются, а уж методы и технологии в ИТ меняются стремительно. И DevOps прямо сейчас эволюционирует в новые методологии, пусть и связанные с ним общими принципами. Кто они, что они, куда ведут нас? И главное — к чему надо инженерам готовиться сегодня, чтобы найти перспективную специализацию завтра?
По прогнозам Nokia Bell Labs объем IP-трафика в 2022 году достигнет уровня в 330 эксабайт в месяц, а количество устройств, подключенных к Интернету вещей, вырастет до 100 млрд в 2025 году. И большую часть сгенерированных устройствами и пользователями данных, так или иначе, будет анализировать бизнес.
Для автоматизации этого процесса будут использоваться платформы обработки и хранения данных, которые дают аналитикам огромные возможности по прогнозированию и глубокому изучению получаемых данных. Однако инфраструктуры таких платформ довольно сложно сопровождать — они содержат много компонентов и связей между ними. А у BI-специалистов свои задачами, им недосуг следить за тем, как, например, распаковывается JSON или извлекаются данные. Так что "платформа ищет человека". И находит его — в лице DataOps- и MLOps-инженеров. Но прежде чем углубиться в эти новые подходы (и, фактически, новые профессии), немного вспомним про их "папу".
Вспомним про DevOps
Как мы все знаем, это методология автоматизации и сопровождения процессов сборки, настройки и развертывания ПО, которая сформировалась в начале 2010 годов. И главный её принцип — это непрерывность. Разработчики тесно взаимодействуют с сотрудниками техподдержки, и вместе они делают всё, чтобы доставить приложение на прод и обеспечить его бесперебойную работу.
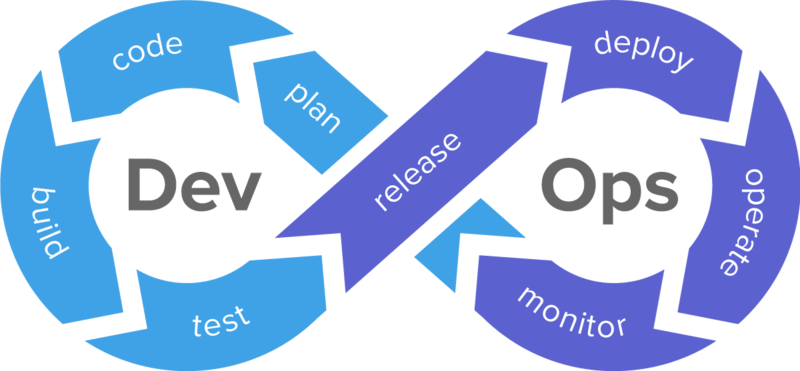
Вот так можно представить процесс разработки web-сервиса методологии по DevOps.
Сейчас главными элементами DevOps-сопровождения можно назвать:
-
Процесс непрерывной доставки кода в среду выполнения.
-
Приложение, которое имеет определённую бизнес-ценность.
-
Круглосуточный доступ к сервису и удовлетворенность конечного пользователя.
В классическом понимании DevOps-команды взаимодействуют с тестерами, разработчиками и системными администраторами. В реальности же это гораздо больше людей. Дополнительно это могут быть и специалисты по информационной безопасности, и менеджеры, и даже клиенты 👇🏻
Резюмируя: если упрощенно представить DevOps, то это подход, объединяющий в один большой процесс приложение, которое видят пользователи, его работоспособность, исходный код и процессы доставки кода в среду выполнения.
DataOps
Время идёт, инфраструктуры меняются, становятся сложнее и обрастают новыми возможностями. Кроме кода и приложения, теперь есть ещё большие, а местами просто гигантские данные, то есть та самая Big Data.
Можно сказать, что DataOps появляется, когда кроме непосредственно кода и среды его выполнения, необходимо ещё и сопровождать потоки данных. То есть это инженеры сопровождения, которые работают уже с несколько другими компетенциями, по большей части связанными с данными и аналитикой.
Почему DataOps сейчас актуален?
Раньше администрированием платформ по работе с данными занимался кто угодно, но не отдельный сотрудник. Это мог быть DevOps в штате, аналитик данных, специалист по машинному обучению (Data Scientist) или кто-то еще. Но с ростом объёма данных растёт и актуальность инженера по DataOps, как отдельного работника. Ценность такого специалиста в том, что он снимает рутинные обязанности с аналитиков и освобождает им больше времени для непосредственной работы.
Повышает востребованность DataOps и то, что работу с данными сейчас продвигают компании, имеющие собственные платформы по обработке и хранению данных. Соответственно, нужны специалисты, которые смогут сопровождать эти решения и обеспечивать их работоспособность.
Чем занимается DataOps?
Весь DataOps-процесс можно представить на такой вот схеме:
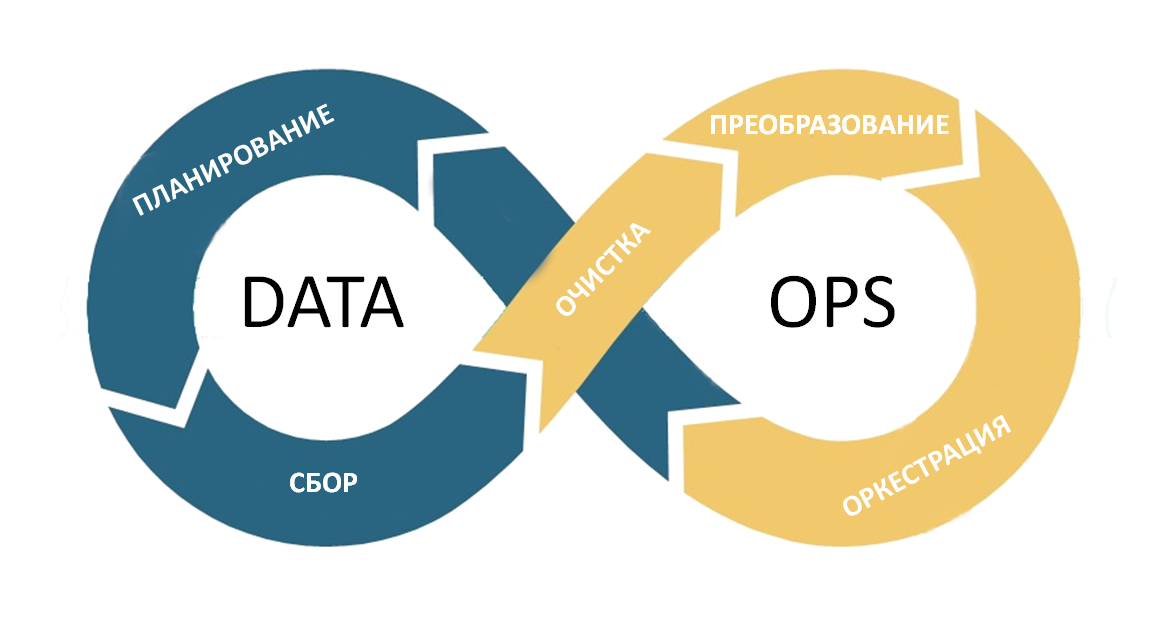
Таким образом, задачи DataOps — сбор данных, их очистка, преобразование, а также оркестрация потоков данных таким образом, чтобы они в нужном виде исправно попадали потребителям этих данных.
Важный аспект в этой работе — проверка качества данных на каждом этапе. Тут всё просто, и этот момент хорошо описывает правило "garbage in — garbage out". Если работать с мусором — некачественными данными, — то и результат будет соответствующий: инсайты ошибочными, а ML-модели вместо умиротворяющих пейзажей станут генерировать реки лавы, озера серы и прочие элементы адского ландшафта. Как в DevOps важна бесперебойная работа приложения, так в работе с данными важна проверка их качества.
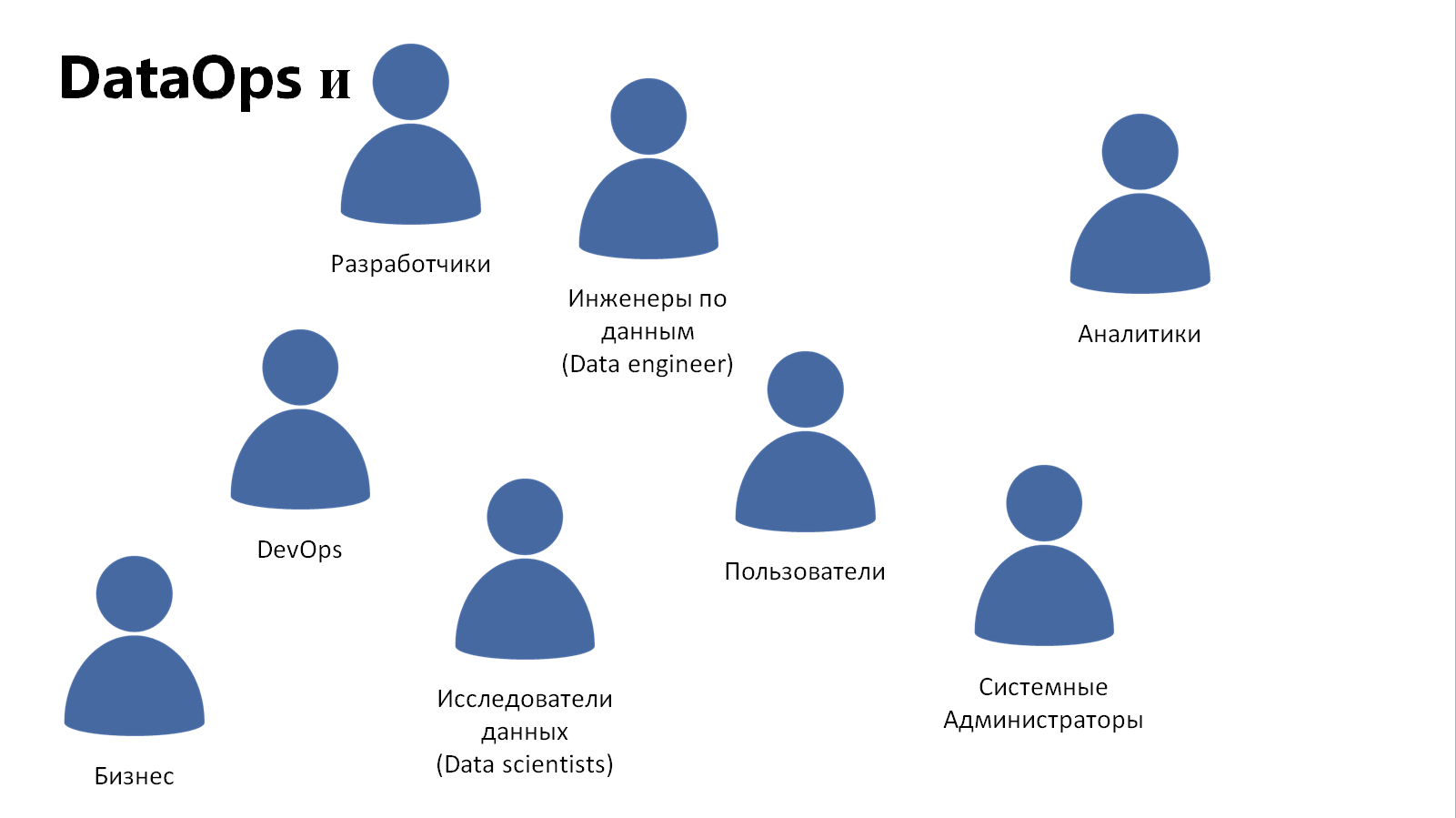
Точно так же, как и DevOps, DataOps работает и с бизнесом, и с пользователем, и с разработчиком, плюс аналитики, инженеры и исследователи данных.
MLOps
MLOps в отличие от DataOps на текущий момент более растиражированная концепция, и про нее можно найти больше информации.
Если вкратце: MLOps — это процесс построения, настройки и поддержки работоспособности инфраструктур, которые на выходе дадут обученную модель машинного обучения.
Актуальность MLOps
Востребованность этой методологии связана с распространением машинного обучения. Сейчас ML-платформы и нейросети используются для самых разных отраслей, от подбора персонала до создания ИИ, способного писать тексты и рисовать картины.
Количество данных, на которых учится MLOps, растёт очень быстро, и с ними необходимо работать: очищать, оркестрировать, преобразовать. При этом специалисты по машинному обучению должны заниматься своими задачами, и у них нет времени на рутину. Вот тут как раз на сцене и появляется MLOps.
Чем занимается MLOps?
Возникает резонный вопрос, чем же MLOps отличается от своего Data-побратима?
Для того чтобы найти ответ, достаточно взглянуть на эту картинку, иллюстрирующую бесконечный MLOps-процесс:
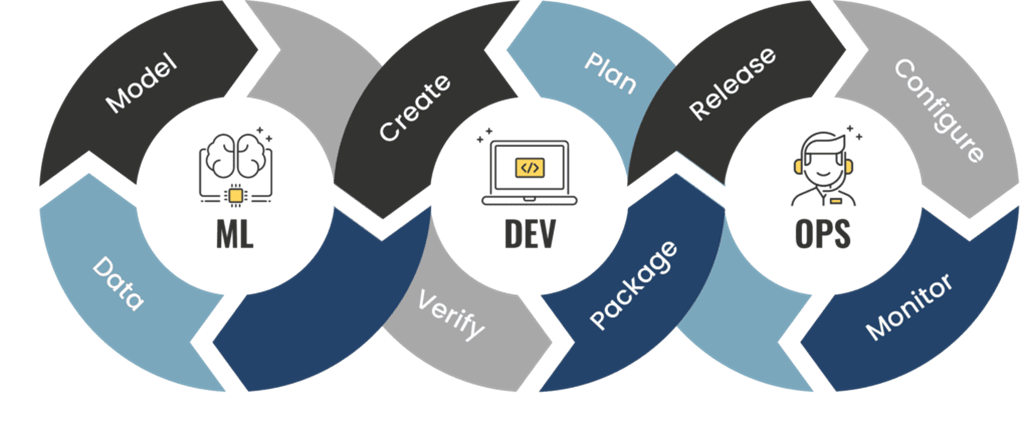
Как видите, добавился ещё один круг и процессов стало 3: сбор, обучение и доставка.
Каждый из этих процессов по-своему сложен. При этом в схеме возникла новая сущность — модель. Кроме того, что нужно извлечь данные и поработать с ними, нужно потом на этих данных ещё и обучить модель. Но не абы какую, а хорошую, ту, которая после доставки в среду выполнения будет приносить какую-то бизнес-ценность.
Ценность работы специалиста по MLOps в том, чтобы все эти процессы работали, данные были качественные и модель обучалась на этих данных. Корреляция тут простая: плохие данные плохо обучат модель, а она даст некачественный результат в среде выполнения. Поэтому ещё нужно следить за качеством самой модели. И мониторить, как функционирует вся цепочка и инфраструктура — от извлечения данных для обучения модели до доставки готовой модели на production.
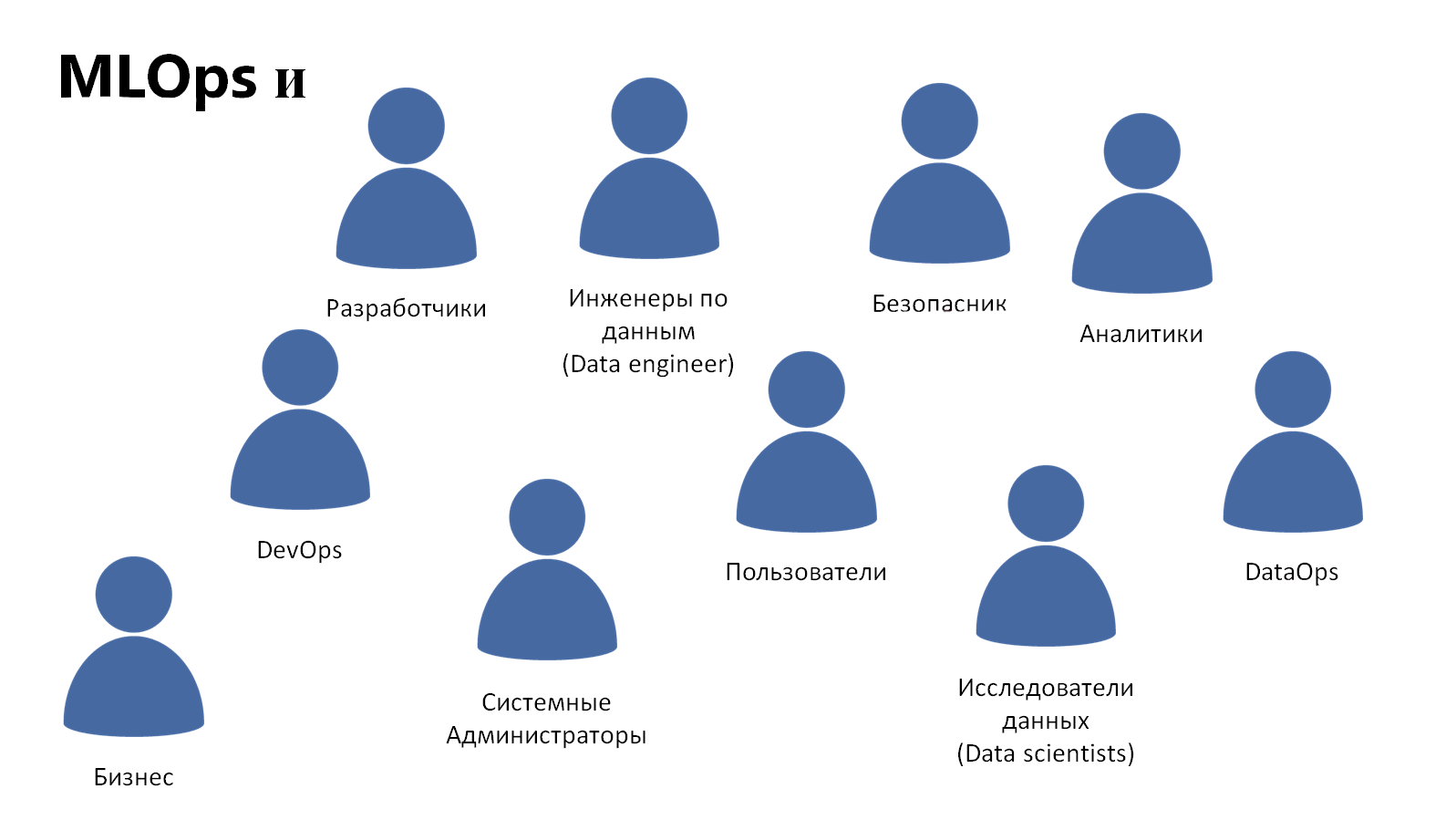
Примерно так выглядит более-менее полный список тех, с кем взаимодействует MLOps.
Кто может стать DataOps и MLOps
Как видите, старина DevOps меняется в сторону специализации. Теперь подход актуален и для таких узкоспециализированных областей, как работа с данными и машинное обучение. Востребованность специалистов, которые могут работать в DataOps и MLOps будет только расти.
Вот наглядный пример — графики интереса к методологиям DevOps, DataOps, MLOps.
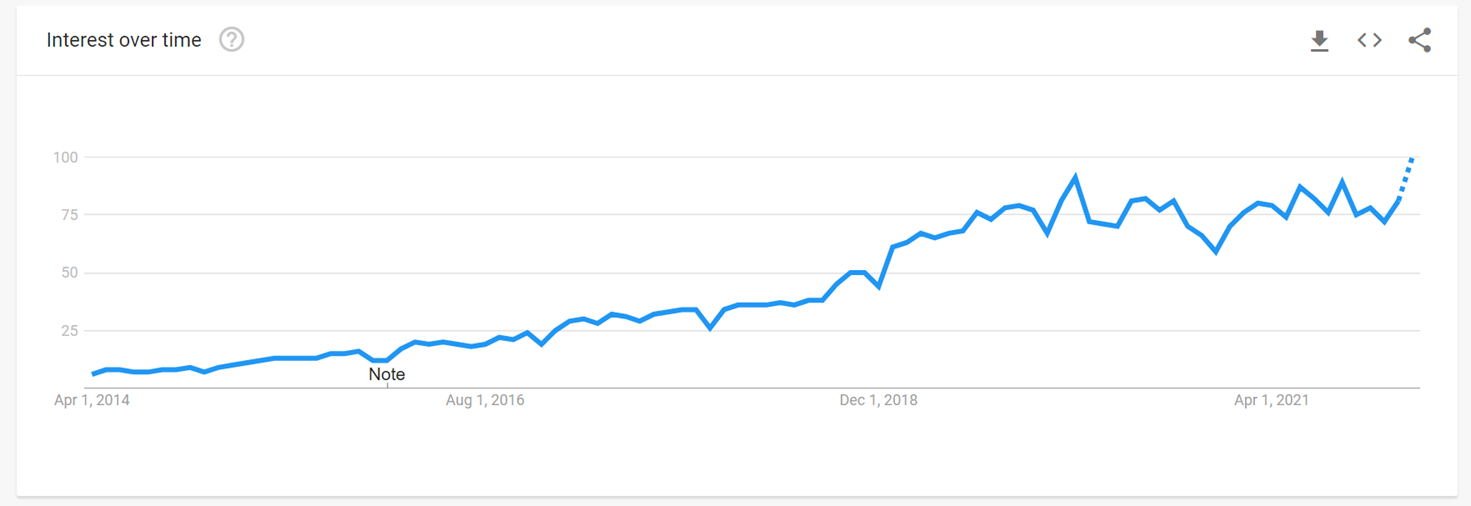
График интереса к DevOps, данные Google. Рост с 2014 года, стабилизация интереса примерно в 2019. Примерно тогда же акцент смещается в сторону работы с данными и ML-моделями.
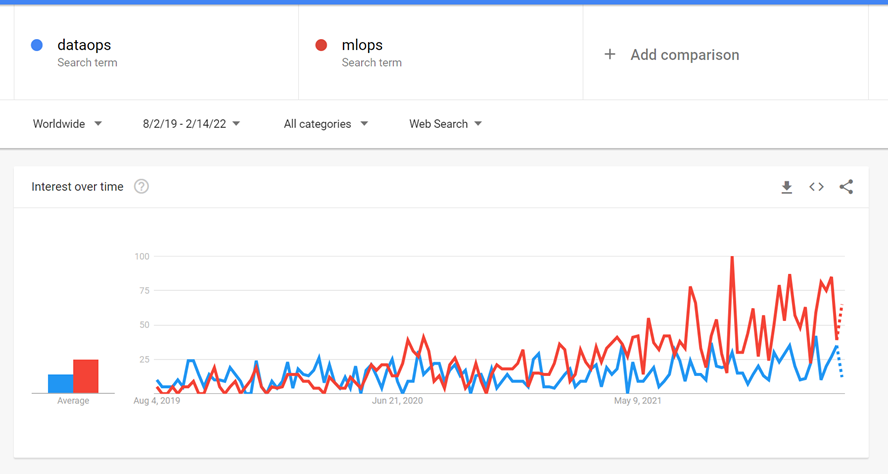
График интереса к DataOps, MLOps. Примерно с августа 2019 в сети стали всё чаще говорить про эти методологии.
Мы предполагаем, что в ближайшие 2-3 года этот интерес только усилится. Поэтому советуем коллегам из команд по эксплуатации обдумать развитие своих компетенции в этом направлении. Особенно если есть интерес в работе с данными и машинном обучении.
Какие технологии нужно изучить и что почитать по теме?
Понять скоуп задач Data и MLOps можно обучая модели и настраивая потоки данных. Для этого подойдут облака, вроде Google Cloud Platform, платформа Azure для машинного обучения или Amazon.
Из стандартных решений, вроде Ansible и Terraform в DevOps, можно выделить Kubeflow. Это своеобразный Kubernetes-дистрибутив с открытым исходным кодом, который работает по принципу On Premise и содержит много ML-инструментов. Другой продукт, но уже не построенный на контейнерах и который стоит выделить — это MLFlow. Он представляет собой уже готовую Open Source платформу для управления жизненным циклом моделей машинного обучения.
Чтобы глубже понимать концепции, которые заложены в методологии, стоит посмотреть Эндрю Ына, одного из основателей Coursera, прошлым летом у него вышло видео про то, как видят MLOps-процесс Data Science специалисты. Почти вся информация по вопросу собрана в гитхабе awesome-mlops, который курирует Лариса Висенгериева, главный эксперт сайта ml-ops.org и кандидат наук по дисциплине «качество данных». Ещё можно почитать блог ML-специалиста Синь Чэня, там есть обстоятельный лонгрид на тему ML и DataOps.
Так что, если вы сейчас DevOps и думаете, как и куда развиваться дальше, то мы настоятельно советуем присмотреться к DataOps и MLOps. Ведь за ними будущее, а как известно, где будущее, там и IT.


