Почему DevOps — это про деньги
Идеи DevOps применимы в практически любых компаниях, которые хотят быстрее развиваться, оперативно реагировать на запросы клиентов — и, конечно, по-настоящему вырасти в выручке и прибыли. Попробуем разобраться, как их внедрить!
Как только заходит речь об успехах в IT, где-то рядом обязательно звучит слово "DevOps". Но это не набор инструментов и указаний на координаты успеха, а способ организации команд и процессов.
Идеи DevOps применимы в практически любых компаниях, которые хотят быстрее развиваться, оперативно реагировать на запросы клиентов — и, конечно, по-настоящему вырасти в выручке и прибыли. Попробуем разобраться, как их внедрить!
Что для этого нужно? И обязательно ли при этом собственнику бизнеса погрузиться в дебри IT?
Давайте рассмотрим один из вариантов реализации DevOps-методологии, который, на наш взгляд, ближе всего к бизнес-задачам. В нём акцент сделан на организационных практиках, многие их которых применимы в наукоёмком и творческом производстве точно также, как и в IT. Но для конкретики примеры будут все-таки из разработки, потому что в ней мы разбираемся лучше, чем в фабриках и заводах.
"Я теряю деньги"
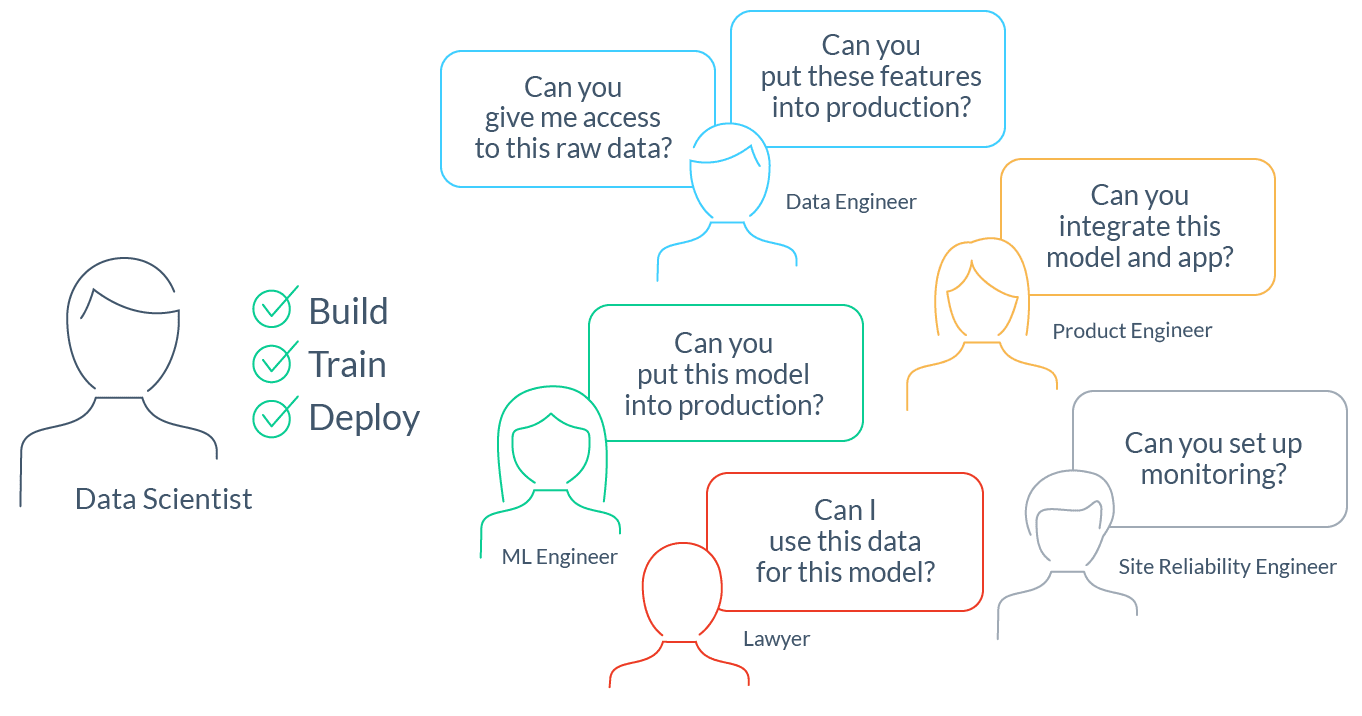
В современной разработке информационных систем есть три основных технических области: разработка, тестирование и эксплуатация. Причем, неважно, говорим мы о продуктовой разработке или об IT-компаниях, которые, как и мы в ITSumma, предоставляют сервисные услуги. Исторически разные специалисты работали над производством программного продукта последовательно. Разработчики писали код, отдавали на тестирование, чтобы не выпустить сырой продукт, а дальше всё это передавалось команде эксплуатации, которая должна была сделать так, чтобы написанный и протестированный код стал доступен пользователям и приносил деньги бизнесу.
На деле же код может путешествовать кругами и перескакивать через несколько ступеней; например, не завестись в продакшен-окружении и вернуться в разработку, или из разработки сразу уйти в эксплуатацию для срочных правок, или застрять в цикле поиска и устранения багов. Каждый такой переход может быть поводом для взаимных претензий и слабым местом. Пока команды перекладывают ответственность и не слишком рьяно стараются договориться, бизнес теряет деньги.
Решение кажется очевидным: совместить три технические области в чем-то одном. Чтобы по одной кнопке код попадал к конечному пользователю и сразу же приносил прибыль. Но как это сделать? С помощью методологии DevOps!
DevOps — методология создания и сопровождения программных продуктов. В её основе активное взаимодействии разработчиков (Dev) и эксплуатации (Ops). Главные принципы этой идеологии описаны в DevOps-манифесте.
Однако споры о том, что входит в понятие DevOps и какой DevOps самый правильный, продолжаются с самого 2009 года, когда впервые появилось само это слово. Мы опираемся на то, как DevOps понимают в книге "Accelerate", которая сейчас воспринимается как Библия DevOps [Nicole Forsgren, Jez Humble, Gene Kim. Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations, 2018].
Что отличает успешные компании от остальных
Авторы "Accelerate" проанализировали несколько тысяч компаний, разрабатывающих информационные системы, и выяснили, какие процессы и подходы помогают больше зарабатывать на программном обеспечении и цифровых инфраструктурах.
Оказалось, что основные отличия высокоэффективных компаний по сравнению с обычными или слабыми выражаются четырьмя характеристиками:
- Частота внесения изменений (deployment frequency) — насколько часто написанный новый код попадает в промышленную эксплуатацию, то есть конечные пользователи получают новые релизы.
- Время внесения изменений (lead time for changes) — от постановки задачи бизнесом до изменений в системе, доступных пользователю; через все шаги разработки, тестирования, отладки и введения в эксплуатацию.
- Среднее время восстановления после аварии (mean time to restoration) — в большей степени эксплуатационная метрика. У одинаковых по симптомам аварий могут быть очень разные причины (резко возросшая нагрузка, ошибки, злонамеренные атаки и т.д.), заранее неизвестно, кому из технических специалистов необходимо подключиться к решению. Но это не волнует бизнес, ведь ему важно быстро вернуть работоспособность сервиса и не терять деньги на простоях.
- Частота аварий, вызванных выкладкой изменений (change failure rate) — то есть как часто наши обновления вызывают проблемы, а не улучшения.
То есть лидеры IT выкладывают изменения практически тут же, как в них возникла необходимость. А все остальные доставляют пользователям обновления в лучшем случае за неделю, а, может, и за полгода: даже для маленькой фичи запускается бюрократическая машина, и обновление попадает к пользователю, когда оно уже никому не нужно.
Успешные компании быстро вносят изменения, допускают не больше 15% провальных релизов и оперативно восстанавливаются, если все-таки что-то пошло не так. Интересно, что аварии чаще случаются у середнячков, чем у аутсайдеров. Это происходит именно потому, что они пытаются быстрее проводить изменения, а те, кто не торопится обновляться, тщательнее проверяют релизы — хоть и выкладывают зачастую то, что может быть уже не нужно.
Так какие процессы в организации помогают быть в топе, быстро развиваться и тут же получать прибыль от нововведений?
Как организованы эффективные команды
Первое, на чём делается акцент при внедрении DevOps и что является ключевым в этой методологии, — это организационная структура. Чтобы добиваться хороших результатов, процесс должен быть предсказуемым. Это значит, что разработка, тестирование и эксплуатация должны работать сообща, а не блокировать работу друг друга и быть как лебедь, рак и щука.
Как ни странно, бизнес-результаты нельзя обеспечить, выбрав определенный состав команды, методологию разработки или направление продукта. По исследованию Google, в котором приняло участие 2,5 тысячи IT-команд, нет видимой связи между тем, насколько команда эффективна с точки зрения бизнеса, и тем, как она устроена. Однако команды можно объединить по общим чертам в организационной структуре. Ниже в таблице один из вариантов классификации — модель Веструма.
В команде, которая ориентируется на результат и имеет высокую производительность, во-первых высокий уровень кооперации между подразделениями. Команды не вставляют палки в колёса друг другу, а идут навстречу, чтобы облегчать коммуникацию и быстрее и эффективнее добиться общей цели.
Сотрудники не боятся высказываться, как в тоталитарных компаниях, а даже наоборот, в некотором смысле, тренируются это делать. Потому что если что-то идет не так, то для достижения результата об этом нужно как можно быстрее узнать. Например, если одна команда ждёт каких-то действий от другой команды, то у неё должна быть возможность сказать об этом. Проблемы решаются быстрее, если их сразу обсудить.
Риски разделяются: если IT-команда не поставила результат, значит вся IT-команда должна перестроиться так, чтобы добиваться желаемого результата. Если рассуждать, как в классическом мире, что баги в коде — это проблемы только разработчиков, то между подразделениями выстраивается стена и они относятся друг к другу враждебно. Но виноваты не люди — виноваты процессы. Поэтому риски разделены между всеми, и, например, в случае ошибок в коде разработчики должны договориться с тестировщиками о том, как им узнавать об ошибках в продакшене, а с эксплуатацией — о том, как можно автоматизировать процесс тестирования, чтобы допускать меньше ошибок. Так все три IT-звена начинают работать сообща и вместе разбираются в проблемах, а не ищут виноватых.
А еще производительные команды быстрее внедряют всё новое. Это звучит достаточно страшно, с продуктовой точки зрения: брать новое, часто сырое и тащить вместе с возможными рисками в промышленную эксплуатацию. Но с другой стороны, чем новее ты используешь технологии, тем быстрее следуешь за рынком, тем быстрее осваиваешь новинки, тем быстрее учишься и т.д. То есть идея не в том, чтобы получать какую-то выгоду от новых инструментов, а в том, чтобы быть гибче и находиться в авангарде IT-инфраструктуры и IT-культуры.
Если IT-команда следует этим принципам, то по исследованию Google скорее всего, эта команда будет работать слаженно и эффективно. Что, в свою очередь, скажется не только на её производительности, но и на успехе всей организации в целом.
Поэтому DevOps начинается с внедрения организационной структуры. То есть с того, чтобы условиться: "мы все будем играть в одну игру по правилам, которые позволят именно нам работать эффективно".
Как на практике перестроить структуру
Недостаточно просто на словах договориться, что отныне мы все вместе несём ответственность за продукт и разделяем риски. Без изменений в процессах неизбежно будут препирания типа: "Это они написали плохой код, почему мы должны отвечать за их ошибки?" Постепенно свести возражения на нет и развернуться в одну строну помогут методы и подходы DevOps. Разберём те из них, которые дают максимальный эффект.
Lean Management, или бережливое производство — концепция управления, которая пошла из компании Toyota. В её основе три принципа:
- маниакальное уменьшение издержек;
- ускорение цепи поставки;
- непрерывное улучшение качества.
Если следовать этим установкам, то организационная культура будет неизбежно меняться в сторону процессов, характерных для высокопроизводительных команд.
Continuous Delivery — важнейшая практика для ускорения цикла производства ПО (и практически единственная в этом списке, применимая исключительно к разработке). Непрерывная интеграция и доставка (CI/CD — Continuous Integration, Continuous Delivery) в современной разработке неразрывно связана с методологией DevOps. Конвейер CI/CD подразумевает, что в процессе разработки в принципе нет разделения на зоны ответственности: все сообща подкручивают гайки так, чтобы конвейер работал, удовлетворяя потребности каждой из команд.
Основная задача программных инструментов непрерывной интеграции и доставки в том, чтобы весь код, вся конфигурация сборки и инфраструктуры были под версионным контролем версий. В процессе доставки не должно использоваться ничего, что написано в процессе доставки — всё должно быть заранее предусмотрено в репозитории и доступно всем командам.
В идеальном DevOps-мире доставка полностью автоматизирована (в данном случае — доставка кода, но с любой другой ценностью для пользователя в целом та же история). При этом автоматическим должен быть и откат изменений. Именно это сочетание и позволяет вносить изменения по запросу и снижать время восстановления после аварии — если версии выкладываются автоматически, то это происходит быстрее и меньше риск человеческой ошибки.
Автоматизация тестирования — нужна как для повышения качества, так и для снижения потерь. Ручное тестирование — это затраты на оплату труда и временные издержки. И как ни странно, ручное тестирование не так хорошо проверяет качество. Да, оно может быть более тщательным и покрывать сложные ситуации, но из-за человеческого фактора вероятность пропустить что-то на самом деле выше. С точки зрения бережливого производства тестирование лучше максимально автоматизировать. Ручное тестирование должно быть только в тех местах, которые не поддаются автоматизации.
Подход Trunk-Based Development (иногда переводят как "магистральная разработка") — заключается в том, чтобы выделить зоны ответственности разных команд и подкоманд. Не все умеют всё, кто-то специалист в работе платёжных систем, кто-то — в масштабировании, кто-то — в загрузке сайта. Эти специализации должны быть четко обозначены, не чтобы перекидывать мячик ответственности, а чтобы в чрезвычайной ситуации обращаться сразу к кому надо и быстрее и эффективнее устранять неполадки. И соответственно уменьшать время восстановления после аварий.
Test Data Management — помогает совершать меньше ошибок, а значит сокращать частоту аварий. Чтобы ошибаться реже, нужно учиться на своих ошибках. А именно: если что-то случилось, то это нужно исправить — и задокументировать то, как исправили и что привело к проблеме, чтобы в дальнейшем не наступать на те же грабли.
Слабосвязанная архитектура — тоже работает на скорость внесения изменений и восстановления после сбоев. Всем известно, чем сильнее связаны между собой системы, тем сложнее их развивать и поддерживать. Более перспективно с этой точки зрения слабая связность, когда части приложения (или производственных процессов) общаются между собой через интерфейсы и проблемы в одной из них не роняют все остальные доминошки. Исключения, конечно, могут быть в ядре, которое критически важно для работы всего проекта, но даже в этом случае, изменения и аварии должны касаться только этого ядра, а не всех связей вокруг него.
Замотивированные команды, у которых есть полномочия. С одной стороны, они необходимы, когда компания ориентируется на результат. С другой — перечисленные практики DevOps естественным образом способствуют мотивации, потому что культура компании исключает токсичность и поиск виноватых, а наоборот ставит понятные, общие для всех цели.
Мониторинг каждого этапа и элемента системы — позволяет, не привлекая людей, определять, что что-то пошло не так, и делать это быстро (в идеале — до того, как проблема проявила себя). То есть в полном соответствии с идеями бережливого производства мониторинг нужен, чтобы экономить и заботиться о качестве.
Проактивная коммуникация — дополняет мониторинг в вопросах, связанных, скорее, с людьми и процессами, чем с программными системами. Цель тут такая же: если есть проблема или блокер, то чем раньше об этом узнают связанные специалисты и ответственная команда, тем быстрее проблема будет решена и тем меньше она повлияет на общий результат и бизнес.
И наконец — как внедрять DevOps
Как видите, получилось, что внедрение DevOps начинается с выстраивания соответствующей культуры, а не с найма DevOps-инженеров. Фактически, компании нужно пройти DevOps-трансформацию, а не просто организовать новый обособленный отдел. Внедрение DevOps — это много работы по изменению принятых в компании процессов, которые при этом надо проводить осознанно, всё время отслеживая результаты, а не экспериментируя на своих людях.
Чтобы взяться за полную DevOps-трансформацию, нужны горящие глаза и холодный расчет. Однако не всегда нужна трансформация всей компании или всего IT-департамента. Например, небольшим или средним компаниям может быть достаточно ускорить выкладку изменений, так как издержки на коммуникации еще небольшие и горизонтальные связи и так отлично работают. В таком случае экономически выгоднее может быть воспользоваться услугами внешних консультантов, которые помогут подстроить правила игры DevOps под конкретные задачи и специфику компании. Или привлечь на отдельные, например, инфраструктурные проекты внешних исполнителей, которые уже живут в парадигме DevOps и вместе с вашей компанией настроят работу над продуктом так, чтобы вы смогли выйти на уровень топовых, высокопроизводительных компаний.
Надеемся, после прочтения этой статьи стало понятнее, в чём польза DevOps для всей компании :-) И кто-то нашел аргументы для своих нетехнических коллег, а кто-то увидел, как DevOps можно применить на только в IT. Если всё сложилось и вы задумались о внедрении DevOps, то не стесняйтесь и сразу приходите к нам за помощью!