Почему нужен DevOps в сфере ML-данных
Фундаментальное препятствие на пути большинства команд к созданию и развертыванию ML в продакшн в ожидаемых масштабах заключается в том, что нам все еще не удалось привнести практики DevOps в машинное обучение. В этой статье мы обсуждаем, почему индустрия нуждается в DevOps решениях для данных ML и как уникальные трудности ML data препятствуют усилиям по практическому применению ML и развертыванию его в продакшн.
Это перевод статьи Кевина Стампфа.
Развертывание машинного обучения (machine learning, ML) в продакшн – задача нелегкая, а по факту, на порядок тяжелее развертывания обычного программного обеспечения. Как итог, большинство ML проектов так никогда и не увидят света — и продакшена — так как большинство организаций сдаются и бросают попытки использовать ML для продвижения своих продуктов и обслуживания клиентов.
Насколько мы можем видеть, фундаментальное препятствие на пути большинства команд к созданию и развертыванию ML в продакшн в ожидаемых масштабах заключается в том, что нам все еще не удалось привнести практики DevOps в машинное обучение. Процесс создания и развертывания моделей ML частично раскрыт уже вышедшими MLOps решениями, однако им недостает поддержки со стороны одной из самых трудных сторон ML: со стороны данных.
В этой статье мы обсуждаем, почему индустрия нуждается в DevOps решениях для данных ML, и как уникальные трудности ML data препятствуют усилиям по практическому применению ML и развертыванию его в продакшн. Статья описывает вакуум в текущей инфрастуктурной экосистеме ML и предлагает заполнить его Tecton, централизованной дата платформой для машинного обучения. По ссылке (англ) от моего со-основателя Майка можно ознакомиться с дополнительными деталями по запуску Tecton.
Tecton был создан группой инженеров, которые создавали внутренние ML платформы в таких компаниях, как Uber, Google, Facebook, Twitter, Airbnb, AdRoll, и Quora. Значимые инвестиции этих компаний в ML позволяли разрабатывать процессы и инструменты по обширному применению ML для своих организаций и продуктов. Уроки, представленные в этой статье, равно как и сама платформа Tecton, во многом основаны на опыте нашей команды по развертыванию ML в продакшн за последние несколько лет.
Помните время, когда выпуск программного обеспечения был долгим и болезненным?
Процесс разработки и развертывания программного обеспечения двадцать лет назад и процесс разработки ML приложений наших дней имеют очень много общего: системы обратной связи оказывались невероятно долгими, и к тому моменту, когда вы добирались до выпуска продукта, ваши изначальные требования и дизайн уже успели устареть. А затем, в конце нулевых, возник набор лучших практик по разработке программного обеспечения в виде DevOps, предоставив методы для управления жизненным циклом разработки и позволив добиться непрерывных, стремительных улучшений.
Подход DevOps позволяет инженерам работать в четко определенной общей кодовой базе. Как только поэтапное изменение готово к развертыванию, инженер проверяет его через систему контроля версий. Процесс непрерывной интеграции и доставки (CD/CI) берет самые последние изменения, проводит модульное тестирование, создает документацию, проводит интеграционное тестирование, и в итоге в управляемой манере выпускает изменения в продакшн либо готовит релиз к распространению.

Рис. 1: типичный DevOps процесс
Ключевые удобства DevOps:
- Программисты владеют своим кодом от начала и до конца. Они наделены полномочиями и полной ответственностью за каждую строку кода в продакшне. Такое чувство сопричастности в целом повышает качество кода, равно как и доступность и надежность программ.
- Команды в состоянии быстро повторять процессы и не сдерживаются длящимися месяцами циклами каскадной модели. Вместо этого они способны тестировать новые возможности с реальными пользователями почти сразу.
- Проблемы производительности и надежности быстро обнаруживаются и анализируются. Если метрики производительности падают сразу после последнего развертывания, срабатывает автоматический откат, а вызвавшие развертывание правки в коде, очень вероятно, являются причиной падения метрик.
В наши дни многими командами разработки взят за основу именно такой интегрированный подход.
…В общем, развертывание ML все еще долгое и болезненное
В явном противоречии с разработкой ПО, в анализе данных нет четко определенных, полностью автоматизированных процессов для быстрого продакшна. Процесс создания ML приложения и развертывания его в продукт состоит из нескольких шагов:

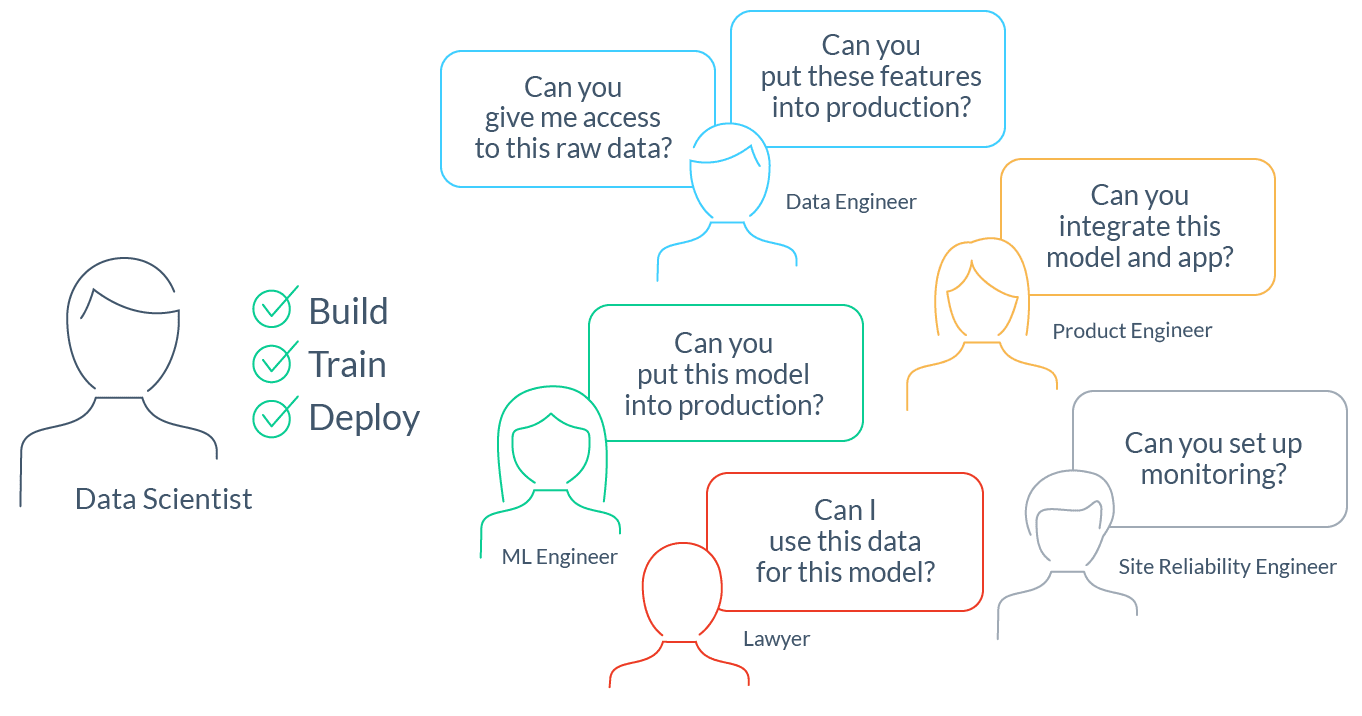
Рис. 2: специалистам анализа данных приходится координировать свою работу между несколькими командами в разных областях
- Обнаружение и доступ к исходным данным. Специалисты data science большинства компаний тратят до 80% своего времени на поиск исходных данных для моделирования своей проблемы. Для этого зачастую требуется кросс-функциональная координация с дата-инженерами и группой нормативного регулирования.
- Разработка функций и тренировка моделей. Как только специалисты анализа данных получают доступ к исходным данным, они зачастую неделями очищают их и преобразуют в функции и метки. Затем они тренируют модели, оценивают результат, и повторяют весь процесс по несколько раз.
- Запуск в производство процессов перемещения и обработки данных. Затем специалисты анализа данных обращаются к программистам за упрощением процессов работы с данными. Обычно это означает передачу кода трансформации функционала следующей команде для эффективной готовой к продакшну реимплементации (подробнее об этом ниже).
- Развертывание и интеграция модели. Этот шаг обычно предполагает интеграцию с сервисом, который использует модель для прогнозирования. Например, мобильное приложение онлайн ритейлера, которое использует рекомендационную модель для прогнозирования предложений по продуктам.
- Настройка мониторинга. В очередной раз, чтобы убедиться в корректной работе модели ML и процессов данных, требуется помощь программистов.
В итоге, команды ML сталкиваются с теми же проблемами, с которыми программисты сталкивались двадцать лет назад:
- У специалистов data science нет полного владения жизненным циклом моделей и функционала. Для развертывания своих правок и поддержки оных в продакшн они вынуждены полагаться на других.
- Специалисты data science не в состоянии быстро повторять процессы. Недостаток владения жизненным циклом делает это невозможным. Для специалистов критична скорость повторения процессов. Однако, у команд, на которые полагаются специалисты data science, достаточно своих задач и приоритетов, что зачастую приводит к вышеупомянутым задержкам и неопределенностям в работе, а они, в свою очередь, накапливаются в огромных количествах и тем самым сводят на нет всю продуктивность.

Рис. 3: И скорость, и частота повторения процессов оказывают значительное давление на кривую ожидаемого улучшения продукта
- Проблемы работоспособности и надежности редко удается определить. Когда программисты реимплементируют работу специалистов data science, становится легко упустить из виду важные детали. Еще легче при этом упустить момент, когда модель в продакшне более не создает корректных прогнозов, так как либо нарушились процессы потоков данных, либо мир изменился и модель требуется переобучить.
DevOps для ML создается полным ходом. Но DevOps для ML data почти нет
Такие MLOps платформы как Sagemaker и Kubeflow движутся в верном направлении по пути помощи компаниям в упрощении производства ML, благодаря чему мы можем наблюдать, как MLOps привносит принципы и инструментарий DevOps в ML. Для начала работы им требуются довольно порядочные авансовые инвестиции, но после корректной интеграции они в состоянии расширить возможности специалистов data science в области обучения, управления и выпуска ML моделей.
К несчастью, бо́льшая часть инструментария MLOps склонна фокусироваться на рабочем процессе вокруг самой модели (обучение, внедрение, управление), что создает ряд трудностей для действующих ML. ML приложения определяются кодом, моделями, и данными. Их успех зависит от способности создавать высококачественные данные ML и поставлять их в продакшн достаточно быстро и стабильно… иначе это очередной «garbage in, garbage out». Следующая диаграмма, специально подобранная и адаптированная из работы Google на тему технического долга в ML, иллюстрирует «датацентричные» и «моделецентричные» элементы в ML системах. В наши дни платформы MLOps помогают с множеством «моделецентричных» элементов, но лишь с несколькими «датацентричными» либо не затрагивают их вовсе:

Рис. 4: Моделе- и атацентричные элементы систем ML. В наши дни моделецентричные элементы в значительной степени покрыты MLOps системами
Следующий раздел демонстрирует некоторые из самых тяжелых испытаний, с которыми нам пришлось столкнуться в ходе упрощения производства ML. Они не являются всеобъемлющими примерами, но рассчитаны показать проблемы, с которыми мы сталкиваемся в ходе управления жизненным циклом ML data (функции и метки):
- Доступ к корректным источникам исходных данных
- Создание функций и меток из исходных данных
- Объединение функций в обучающие данные
- Вычисление и выдача функций в продакшн
- Отслеживание функций в продакшне
Небольшое напоминание, прежде чем мы погрузимся дальше: функция ML это данные, которые служат входящим сигналом для принятия решения моделью. Например, сервис доставки еды хочет в своем приложении показывать ожидаемое время доставки. Для этого необходимо предугадать длительность готовки конкретного блюда, в конкретном ресторане, в конкретное время. Одним из удобных сигналов для создания такого прогноза — прокси для того насколько ресторан загружен — будет «конечный счет» входящих заказов за последние 30 минут. Функция рассчитывается исходя из потока исходных данных порядка заказов:

Рис. 5: Исходные данные меняются функцией трансформацией в значения функций
Дата-испытание #1: Получение доступа к корректным исходным данным
Для создания любой функции или модели специалисту data science в первую очередь необходимо обнаружить корректный источник данных и получить к нему доступ. На этом пути есть несколько препятствий:
- Обнаружение данных: Специалисты должны знать, где находятся исходные данные. Отличным решением являются системы каталогизации данных (например Lyft`s Amundsen), но они пока еще не применяются столь повсеместно. Зачастую необходимые данные попросту не существуют и потому сначала должны быть созданы или каталогизированы.
- Одобрение доступа: Зачастую беготня между инстанциями для получения разрешений на доступ к данным, которые позволят решить проблемы, это обязательный этап на пути специалистов data science.
- Доступ к исходным данным: Специалисты могут извлечь исходные данные единым дампом данных, который устареет тут же, как окажется на их ноутбуке. Или они могут продираться сквозь проблемы сетевого взаимодействия и аутентификации, чтобы затем сталкиваться с необходимостью выуживать исходные данные из источников специфическими языками запросов.
Дата-испытание #2: Создание функций из исходных данных
Исходные данные могут поступать из множества источников, каждый со своими, влияющими на извлекаемые из них типы функций, важными свойствами. Эти свойства включают в себя поддержку источником данных типов трансформации, актуальности данных, и объема доступного архива данных:

Рис. 6: Различные источники данных по-разному подходят к различным типам трансформации данных и предоставляют доступ к различным объемам данных в зависимости от актуальности
Важно учитывать эти свойства, так как типы источников данных определяют типы функций, которые специалист data science может получить из исходных данных:
- Хранилища данных (например Snowflake и Redshift) хранят множество информации с низкой актуальностью данных (часы и дни). Они могут оказаться золотой жилой, но лучше всего подходят для широкомасштабной агрегации с низкими требованиями к актуальности, например «количество всех транзакций на каждого пользователя».
- Транзакционные источники данных (такие как MongoDB или MySQL) в основном хранят меньшие объемы данных с большей актуальностью и не рассчитаны на работу с большими аналитическими трансформациями. Они лучше всего подходят для агрегации небольшого масштаба с малым промежутком времени, например количество созданных пользователем заказов за последние 24 часа.
- Потоки данных (например Kafka) хранят высокоскоростные события и предоставляют их почти в реальном времени (в районе миллисекунд). Стандартные потоки хранят от одного до семи дней архивных данных. Они хорошо подходят для агрегации в коротких промежутках времени и простых трансформаций с высокими требованиями к актуальности, например вычисления приведенной выше функции «конечного счета поступающих заказов за последние 30 минут».
- Данные запросов прогнозирования это исходные данные событий, которые возникают в реальном времени прямо перед тем как совершается ML прогноз, например, только что введенный пользователем в строку поиска запрос. Пусть такие данные и лимитированы, зачастую они «свежи» настолько насколько возможно и содержат легко прогнозируемый сигнал. Подобные данные поступают с запросом прогнозирования и могут использоваться в таких вычислениях в реальном времени как поиск оценки сходства между поисковым запросом пользователя и документами поисковом массиве.
Забегая вперед, обращаем внимание: комбинирование данных из разных источников с взаимодополняющими характеристиками позволяет создавать действительно хорошие функции. Подобный подход требует реализации и управления более совершенными трансформациями функций.
Дата-испытание #3: Объединение функций в обучающие данные
Формирование обучающих или тестовых наборов данных требует объединения данных соответствующих функций. При этом необходимо отслеживать множество деталей, способных оказывать критические воздействия на модель. Двумя наиболее коварными из них являются:
- Утечка данных: Специалистам data science необходимо обеспечивать обучение своей модели на корректной информации и не допускать «утечки» нежелательной информации в обучающие данные. Такими данными могут быть: данные из тестового набора, данные ground truth, данные из будущего, или нарушающая важные подготовительные процессы (например анонимизацию) информация.
- Путешествия во времени: Данные из будущего — особо проблемный тип утечки данных. Предотвращение подобной утечки требует аккуратного вычисления значения каждой функции в обучающих данных относительно конкретного времени в прошлом (то есть путешествие во времени к конкретной точке времени в прошлом). Обычные системы данных не рассчитаны на поддержку путешествий во времени, что заставляет специалистов data science принять утечку данных в их модели за данность, либо же нагромождать целые джунгли из костылей для корректной работы системы.
Дата-испытание #4: Вычисление и выдача функций в продакшн
После того как модель выпущена в работу в реальном времени, для создания корректных и актуальных прогнозов ей требуется постоянно поставлять новые данные функций — зачастую масштабно и с минимальным временем ожидания.
Каким образом нам следует передавать модели эти данные? Напрямую из источника? Получение и передача данных из хранилища может занять минуты, дни, часы, или даже дни, что слишком долго для вывода данных в реальном времени и потому в большинстве случаев невозможно.

В таких случаях, вычисление функций и потребление функций необходимо расцепить. Для предварительного вычисления (пред-вычисления) функций и отгрузки их в оптимизированное для выдачи хранилище данных продакшна необходимо воспользоваться процессами ETL. Эти процессы создают дополнительные сложности и требуют новых трат на обслуживание:

Поиск оптимального компромисса между актуальностью и рентабельностью: Расцепка вычисления и потребления функций присваивает актуальности первоочередное внимание. Зачастую, за счет повышения стоимости, процессы функций могут прогоняться чаще и как следствие выдавать более актуальные данные. Корректный компромисс колеблется в зависимости от функций и вариантов использования. Например, функция агрегации тридцатиминутного окна конечного счета по доставке будет иметь смысл, если ее будут обновлять чаще, чем похожую функцию с двухнедельным окном конечного счета.

Интегрирование процессов функций: Ускорение производства функций требует получения данных из нескольких различных источников, и как следствие разрешения связанных с этим проблем, более сложных, чем как при работе лишь с одним источником данных, которые мы обсуждали до этого. Координация таких процессов и интеграция их результатов в единый вектор функций требует серьезного подхода со стороны инжиниринга данных.
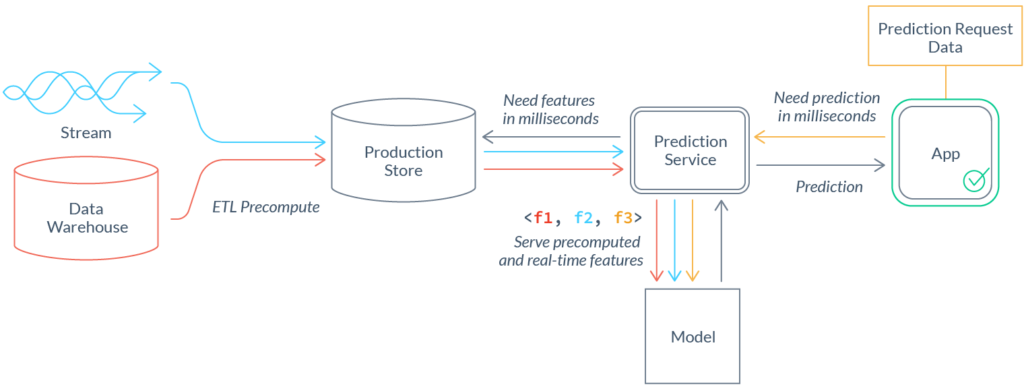
Недопущение искажений при обучении (training/serving-skew): Расхождения между результатами процессов обучения и работы могут привести к искажениям при обучении. Искажения при обучении довольно сложно обнаружить, а их наличие может привести в негодность прогнозы модели. Модель может повести себя хаотично при выводе заключений на основе данных, сгенерированных отлично от тех на которых она обучалась. Сам по себе вопрос искажений и работы с ними заслуживает отдельной серии статей. Тем не менее, стоит выделить два типичных риска:
- Логические расхождения: При различии в имплементации процессов обучения и работы (как это и бывает в обычной практике) легко столкнуться с различиями в логике трансформации, и даже незначительные на вид несоответствия могут привести к огромным негативным последствиям. Различно ли обрабатываются Null? Согласована ли у чисел точность знака после запятой? Лучшими практиками по минимизации риска любого подобного искажения является переиспользование как можно большего трансформационного кода между обучающими и рабочими процессами. Трата значительных дополнительных усилий на минимизацию рисков подчеркивает важность подобных практик и позволяет сохранить бессчетное количество часов болезненной отладки в будущем.

Рис. 7 В целях недопущения искажений при обучении следует пользоваться единым методом реализации функций для и обучающих, и рабочих процессов
- Временны́е искажения: Постоянное пред-вычисление функций не проводится по ряду причин (обычно таких как стоимость). Например, перевычисление в продакшне двухчасового конечного счета заказов за каждого пользователя и каждую секунду создает слишком незначительный, и потому не стоящий такой траты ресурсов, дополнительный сигнал. На практике, к моменту вывода данных значения функций могут устареть на несколько минут, часов и даже дней. Отсутствие отображения такого простоя в обучающих данных — одна из типичных ошибок, результатом которой становится обучение модели на данных более актуальных, чем те, которые она получит на продакшне.
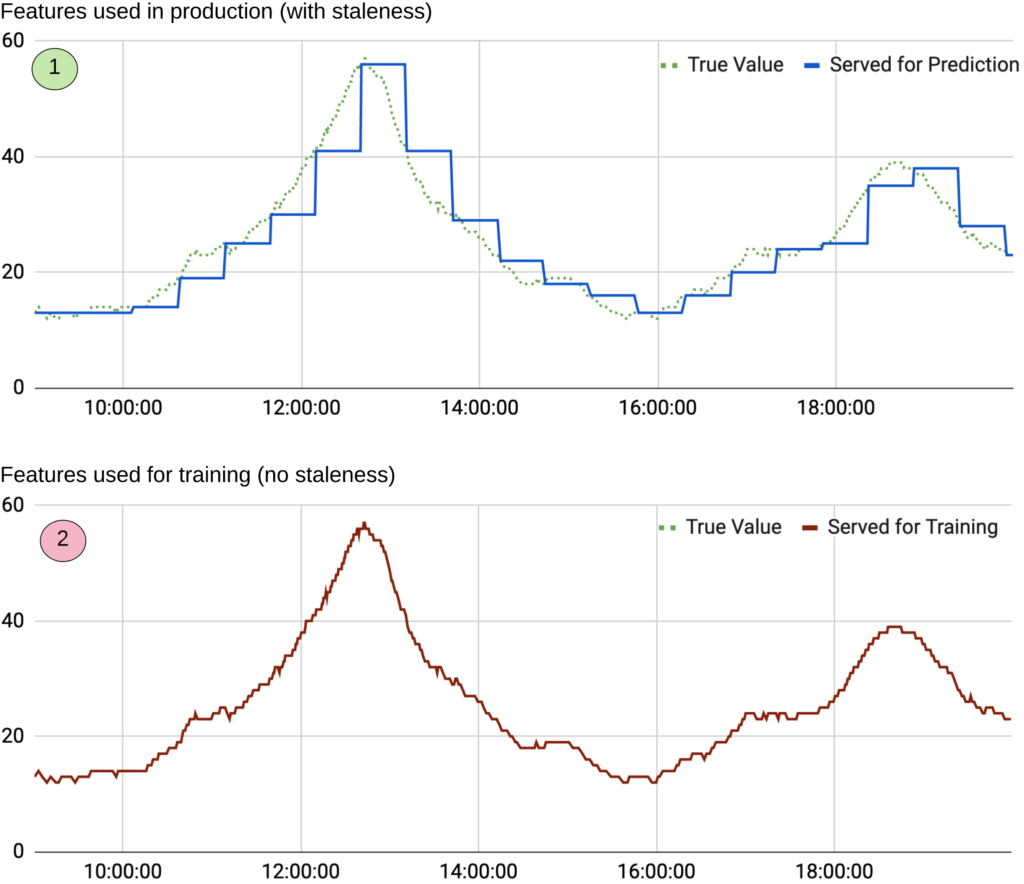
Рис. 8: График показывает конечный счет заказов: на (1) изображены значения функции, выданные для прогноза и обновляемые каждые 10 минут; на (2) изображены обучающие данные, которые некорректно отображают истинные значения намного четче по сравнению с функциями, выданными на продакшн
Дата-испытание #5: Отслеживание функций на продакшне
Что-нибудь да будет ломаться, не смотря на все попытки корректно обходить указанные выше проблемы. Когда ML система ломается, почти всегда это случается из-за «нарушения целостности данных». Данный термин может указывать на множество различных причин, каждая из которых требует отслеживания. Примеры нарушения целостности данных:
- Сломанный канал передачи источника данных: Источник исходных данных может испытывать перебои в работе и внезапно начать передавать некорректные данные, передавать данные с задержкой, или перестать передавать данные вовсе. Перебои с данными могут иметь широкий круг косвенных последствий, засоряя функции и модели канала загрузки, и очень легко не заметить возникновение подобного перебоя. И даже если перебои удается идентифицировать, решение проблемы дозаполнением оказывается слишком дорогим и труднодоступным.
- Дрейф действующих функций: Отдельные функции модели могут начать дрейфовать, то есть перестают быть актуальными для текущих задач. Причиной этого может быть как баг, так и самое обычное нормальное поведение модели, что обычно является индикатором перемен в мире (например, поведение ваших пользователей может резко измениться после очередного выпуска новостей), что в свою очередь требует переобучения модели.
- Непрозрачные перебои функций групп населения: Обнаружить перебои во всей функции достаточно тривиально. Однако обнаружить перебои, которые затрагивают только одну или несколько групп либо подгрупп населения (например, только пользователей, проживающих в Германии) значительно труднее.
- Невыясненная ответственность за качество данных: В случае, когда функции могут получать исходные данные от нескольких различных раздающих источников, кто в итоге отвечает за качество функции? Специалист data-science, который создал функцию? Специалист data-science, который обучил модель? Владелец канала отдачи данных? Программист, который провел интеграцию модели в продакшн? В случаях, когда ответственности неясны, проблемы слишком долго остаются нерешенными.
Подобные испытания создают почти непреодолимую полосу препятствий даже для самых продвинутых команд в области data science и ML engineering. Для их решения требуется нечто лучшее, чем неизменный статус-кво большинства компаний, когда индивидуальные решения на заказ остаются единственным ответом на подмножество этих проблем.
Представляем Tecton: дата платформу для машинного обучения
В Tecron мы создаем дата платформу для машинного обучения чтобы предоставить помощь с самыми обычными и самыми тяжелыми проблемами в области data science.
На высоком уровне, платформа Tecron имеет в себе:
- Процессы функций для превращения ваших исходных данных в функции и метки
- Хранилище функций для хранения архивных данных функций и меток
- Сервер функций для выдачи последних значений функции на продакшн
- SDK для получения обучающих данных и манипулирования процессами функций
- Web UI для контроля и отслеживания функций, меток и наборов данных
- Мониторинговый движок для определения качества данных либо проблем дрейфа, и оповещения
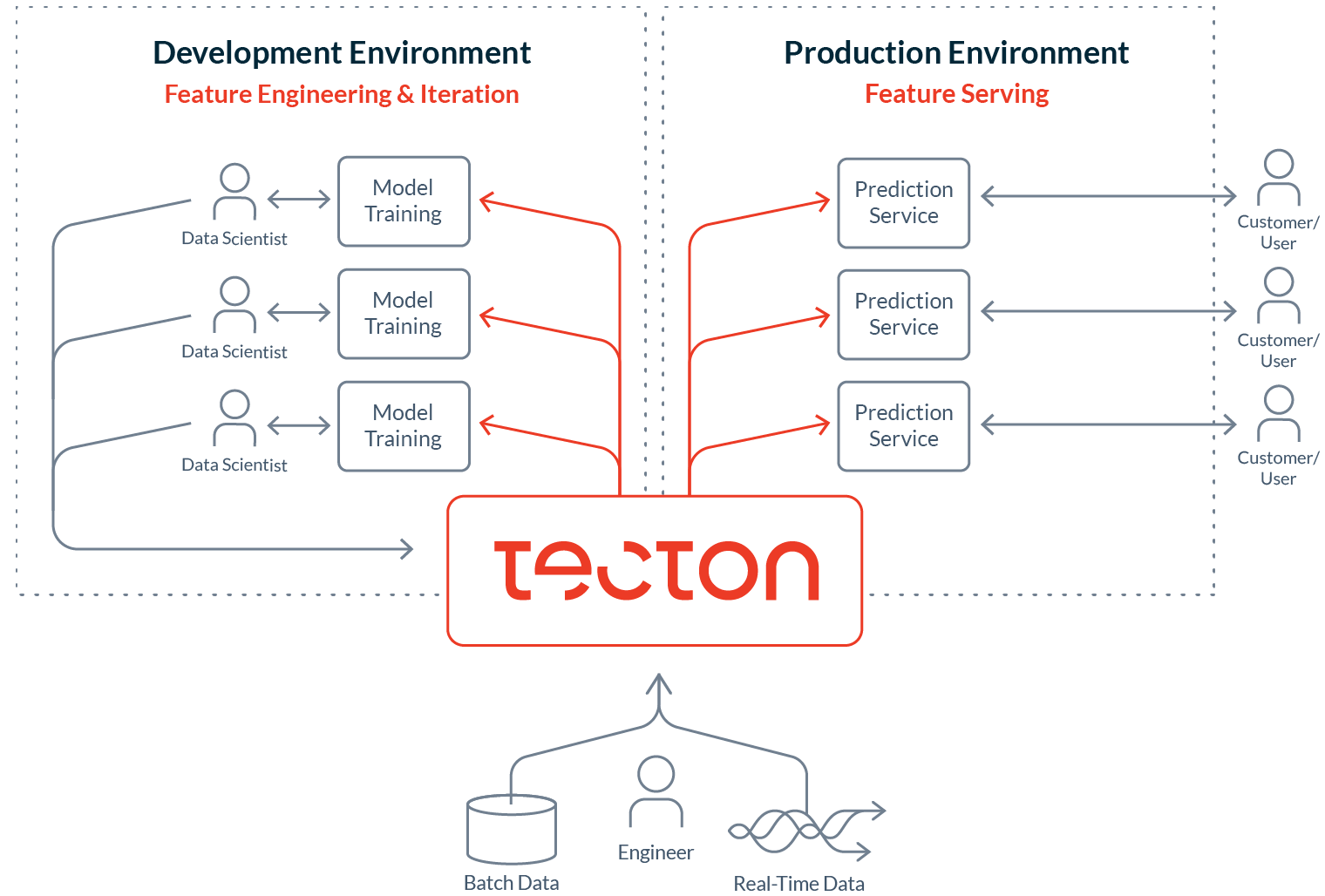
Рис. 9: Будучи центральной дата платформой для ML, Tecton выдает функции в среды разработки и продакшна
Платформа позволяет командам ML привнести практики DevOps в ML data:
- Планирование: Функции Tecron хранятся в центральном репозитории. Это позволяет специалистам data science делиться, находить и пользоваться трудами друг друга.
- Код: Tecton позволяет пользователям устанавливать простые и гибкие процессы трансформаций функций.
- Сборка: Tecton компилирует функции в производительные задачи обработки данных.
- Тестирование: Tecton поддерживает функциональное и интеграционное тестирование функций.
- Релиз: Tecton тесно интегрируется с git. Все описания функций имеют контроль версий и легко воспроизводятся.
- Развертывание: Tecton развертывает и организовывает выполнение задач обработки данных на движках обработки данных (таких как Spark). Эти процессы данных постоянно доставляют данные функций в хранилище функций Tecron.
- Оперирование: Сервер функций Tecton предоставляет последовательные значения функций специалистам data science как для обучения моделей, так и для моделей в продакшне для прогнозов.
- Мониторинг: Tecton отслеживает входящий и исходящий поток процессов функций на случай дрейфа и проблем с качеством данных.
Конечно, ML data без ML модели не дадут вам практической реализации ML. Поэтому Tecton предоставляет гибкие API и интегрируется с уже существующими ML платформами. Мы начали с Databricks, SageMaker и Kuberflow, и продолжаем интегрироваться с взаимодополняющими компонентами экосистемы.


