
Как мы сайт Republic на Kubernetes переводили
В ходе переезда ни один технический специалист Republic не пострадал...
Скандальные, важные и просто очень крутые материалы выходят в СМИ не каждый день, да и со 100% точностью спрогнозировать успешность той или иной статьи не возьмётся ни один редактор. Максимум, чем располагает коллектив — на уровне чутья сказать, «крепкий» материал или же «обычный». Все. Дальше начинается непредсказуемая магия СМИ, благодаря которой статья может выйти в топы поисковой выдачи с десятками ссылок от других изданий или же материал канет в Лету. И вот как раз в случае публикации крутых статей сайты СМИ периодически падают под чудовищным наплывом пользователей.
Этим летом жертвой профессионализма собственных авторов стал сайт издания Republic: статьи на тему пенсионной реформы, о школьном образовании и правильном питании в общей сложности собрали аудиторию в несколько миллионов читателей. Публикация каждого упомянутого материала приводила к настолько высоким нагрузкам, что до падения сайта Republic оставалось совсем «вот столечко». Администрация осознала, что надо что-то менять: нужно было изменить структуру проекта таким образом, чтобы он мог живо реагировать на изменение условий работы (в основном, внешней нагрузки), оставаясь полностью работоспособным и доступным для читателей даже в моменты очень резких скачков посещаемости. И отличным бонусом было бы минимальное ручное вмешательство технической команды Republic в такие моменты.
По итогам совместного со специалистами Republic обсуждения различных вариантов реализации озвученных хотелок мы решили перевести сайт издания на Kubernetes. О том, чего нам всем это стоило, и будет сегодняшний рассказ.
Как это выглядело в общих чертах
Началось всё, само собой, с переговоров, как всё будет происходить «сейчас» и «потом». К сожалению, современная парадигма на IT-рынке подразумевает, что как только какая-либо компания отправляется на сторону за каким-то инфраструктурным решением, то ей подсовывают прейскурант услуг «под ключ». Казалось бы, работы «под ключ» — что может быть приятнее и милее условному директору или владельцу бизнеса? Заплатил, и голова не болит: планирование, разработка, поддержка — все находится там, на стороне подрядчика, бизнесу же остаётся лишь зарабатывать деньги на оплату столь приятного сервиса.
Однако полная передача IT-инфраструктуры не во всех случаях целесообразна для заказчика в долгосрочной перспективе. Правильнее со всех точек зрения работать одной большой командой, чтобы после завершения проекта клиент понимал, как жить с новой инфраструктурой дальше, а у коллег по цеху со стороны заказчика не было вопроса «ой, а что это тут наворотили?» после подписания акта выполненных работ и демонстрации результатов. Того же мнения придерживались и парни из Republic. В итоге мы на два месяца высадили десант из четырёх человек к клиенту, которые не только реализовали нашу задумку, но и технически подготовили специалистов на стороне Republic к последующей работе и существованию в реалиях Kubernetes.
И выиграли от этого все стороны: мы быстро выполнили работу, сохранили своих специалистов готовыми к новым свершениям и получили Republic в качестве клиента на консультативной поддержке с собственными инженерами. Издание же получило новую инфраструктуру, приспособленную к «хабраэффектам», собственный сохранённый штат технических специалистов и возможность обратиться за помощью, если она потребуется.
Готовим плацдарм
«Разрушать — не строить». Поговорка эта применима вообще к чему угодно. Конечно, наиболее простым решением кажутся упоминаемый ранее захват инфраструктуры клиента в заложники и приковывание его, клиента, к себе цепью, ну или разгон имеющегося штата и требование нанять гуру в новых технологиях. Мы пошли третьим, не самым популярным нынче путём, и начали с обучения инженеров Republic.
Примерно такое решение по обеспечению работы сайта мы увидели на старте:
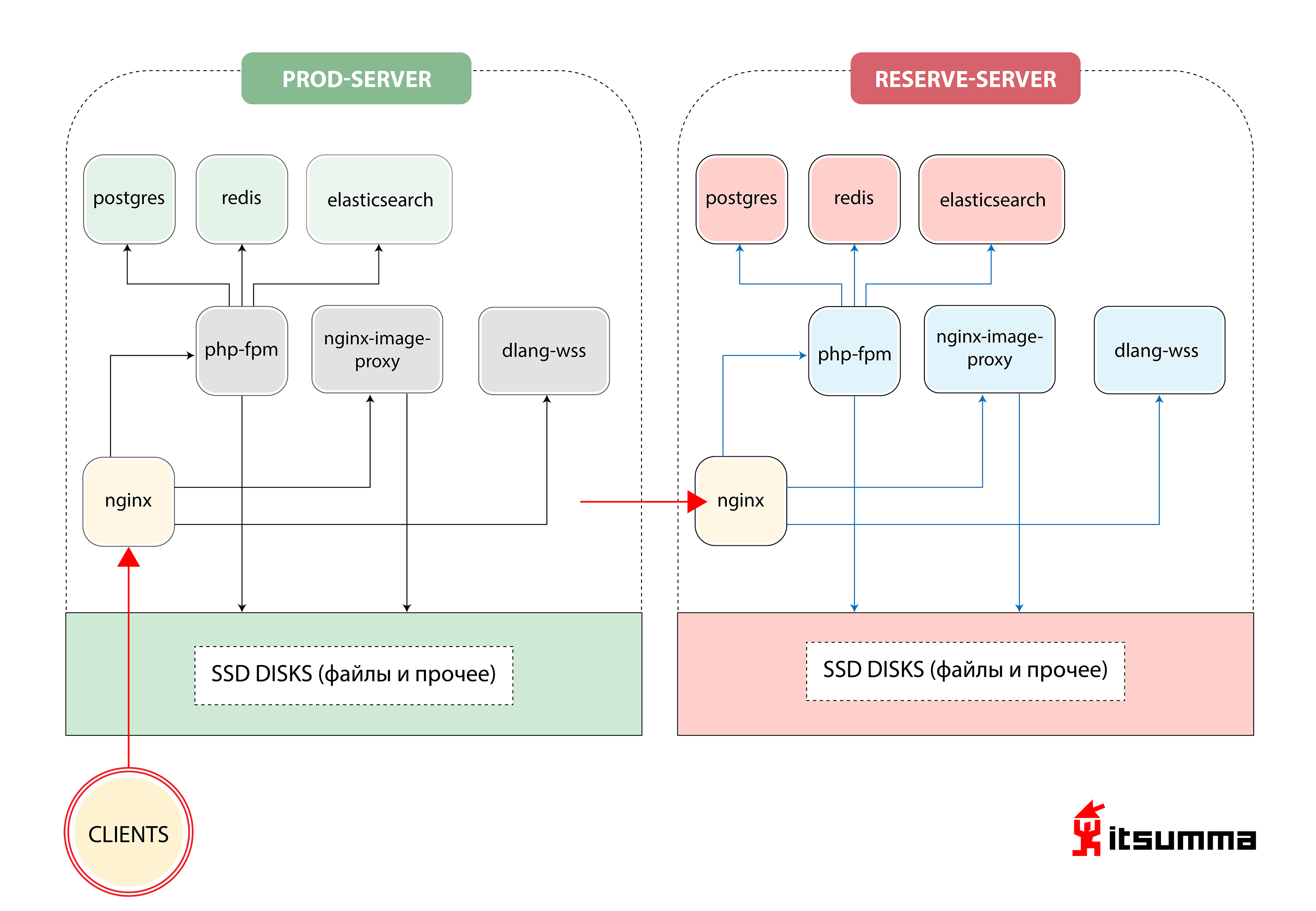
То есть, у Republic было просто два железных сервера — основной и дублирующий, резервный. Самым важным для нас было добиться смены парадигмы мышления технических специалистов клиента, потому что ранее они имели дело с весьма простой связкой из NGINX, PHP-fpm и PostgreSQL. Теперь же им предстояло столкнуться с масштабируемой контейнерной архитектурой Kubernetes. Так что вначале мы перевели локальную разработку Republic на docker-compose окружение. И это был только первый шаг.
До высадки нашего десанта разработчики Republic держали свое локальное рабочее окружение в виртуальных машинах, конфигурируемых через Vagrant, либо же работали напрямую с dev-сервером по sftp. Исходя из общего базового образа виртуальной машины, каждый разработчик «доконфигурировал» свою машинку «под себя», что порождало целый набор различных конфигураций. Как следствие подобного подхода, подключение в команду новых людей экспоненциально увеличивало время их входа в проект.
В новых реалиях мы предложили команде более прозрачную структуру рабочего окружения. В ней декларативно описали, какое ПО и каких версий нужно для проекта, порядок связей и взаимодействия между сервисами (приложениями). Это описание залили в отдельный git-репозиторий, чтобы им можно было удобно централизованно управлять.
Все нужные приложения стали запускаться в отдельных docker-контейнерах — а это обычный php-сайт с nginx, много статики, сервисы для работы с изображениями (ресайз, оптимизация и т д), и… отдельный сервис для веб-сокетов, написанный на языке D. Все файлы конфигураций (nginx-conf, php-conf…) тоже стали частью кодовой базы проекта.
Соответственно, было «воссоздано» и локальное окружение, полностью идентичное текущей серверной инфраструктуре. Таким образом была снижены времязатраты на поддержание одинакового окружения как на локальных машинах разработчиков, так и на проде. Что, в свою очередь, сильно помогало избегать совершенно ненужных проблем, вызываемых самописными локальными кофигурациями каждого разработчика.
В результате в docker-compose среде были подняты следующие сервисы:
- web для работы php-fpm приложения;
- nginx;
- impproxy и cairosvg (сервисы для работы с изображениями);
- postgres;
- redis;
- elastic-search;
- trumpet (тот самый сервис для web-сокетов на D).
С точки зрения разработчиков работа с кодовой базой осталась неизменной — в нужные сервисы она монтировалась из отдельной директории (базовый репозиторий с кодом сайта) в нужные сервисы: public-директория в nginx-сервис, весь код php-приложения в php-fpm-сервис. Из отдельной директории (в которой содержатся все конфиги compose-окружения) в nginx- и php-fpm- сервисы монтируются соответствующие файлы конфигураций. Директории с данными postgres, elasticsearch и redis также монтируются на локальную машину разработчика, чтобы в случае, если все контейнеры придётся пересобрать/удалить, данные в этих сервисах не были потеряны.
Для работы с логами приложений — также в docker-compose окружении — были подняты сервисы ELK-стека. Раньше часть логов приложений писались в стандартные /var/log/…, логи и эксепшены php-приложений писались в Sentry, и такой вариант «децентрализованного» хранения журналов был крайне неудобен в работе. Теперь же приложения и сервисы были сконфигурированы и доработаны для взаимодействия с ELK-стеком. Оперировать логами стало гораздо проще, у разработчиков появился удобный интерфейс для поиска, фильтрации логов. В дальнейшем (уже в кубике) — можно смотреть логи конкретной версии приложения (например, кронжобы, запущенной позавчера).
Далее у команды Republic начался небольшой период адаптации. Команде нужно было понять и научиться работать в условиях новой парадигмы разработки, в которой необходимо учитывать следующее:
- Приложения становятся stateless, и у них в любой момент могут пропасть данные, поэтому работа с базами данных, сессиями, статичными файлами должна быть построена иначе. PHP-сессии должны храниться централизованно и шариться между всеми инстансами приложения. Это могут продолжать быть файлы, но чаще для этих целей берут redis из-за большего удобства управления. Контейнеры для баз данных должны либо «монтировать в себя» датадиру, либо БД должна быть запущена вне контейнерной инфраструктуры.
- Файловое хранилище из порядка 50-60 Гб картинок не должно находиться «внутри веб-приложения». Для таких целей необходимо использовать какое-либо внешнее хранилище, cdn-системы и т.д.
- Все приложения (базы данных, аппликейшен-серверы…) теперь являются отдельными «сервисами», и взаимодействие между ними должно конфигурироваться относительно нового пространства имен.
После того, как команда разработки Republic освоилась с нововведениями, мы начали перевод продовой инфраструктуры издания на Kubernetes.
А вот и Kubernetes
На основе построенного для локальной разработки docker-compose окружения мы начали переводить проект в «кубик». Все сервисы, на которых проект построен локально, мы «запаковали в контейнеры»: организовали линейную и понятную процедуру сборки приложений, хранения конфигураций, компилирования статики. С точки зрения разработки — вынесли нужные нам параметры конфигураций в переменные окружения, стали хранить сессии не в файлах, а в редисе. Подняли тестовую среду, где развернули работоспособную версию сайта.
Так как это бывший монолитный проект, очевидно, что имела место быть жёсткая зависимость между версиями фронтенда и бекенда — соответственно, и деплоились эти два компонента одновременно. Поэтому поды web-приложения мы решили построить таким образом, чтобы в одном поде крутилось сразу два контейнера: php-fpm и nginx.
Мы построили также автоскейлинг, чтобы web-приложения масштабировались максимум до 12 в пике трафика, поставили определённые liveness/readiness пробы, потому что приложение требует как минимум 2 минуты на запуск (поскольку нужно прогреть кэш, сгенерировать конфиги…)
Тут же, конечно, нашлись всякие косяки и нюансы. Например: скомпиленная статика была необходима как web-серверу, который её раздавал, так и application-серверу на fpm’е, который где-то на лету генерировал какие-то картинки, где-то прямо кодом отдавал svg. Мы поняли: чтобы два раза не вставать, нужно создать промежуточный build-контейнер и финальную сборку контейнеризировать через multi-stage. Для этого мы создали несколько промежуточных контейнеров, в каждом из которых зависимости подтягиваются отдельно, потом отдельно собирается статика (css и js), и после в два контейнера — в nginx и в fpm— они копируются из промежуточного build-контейнера.
Стартуем
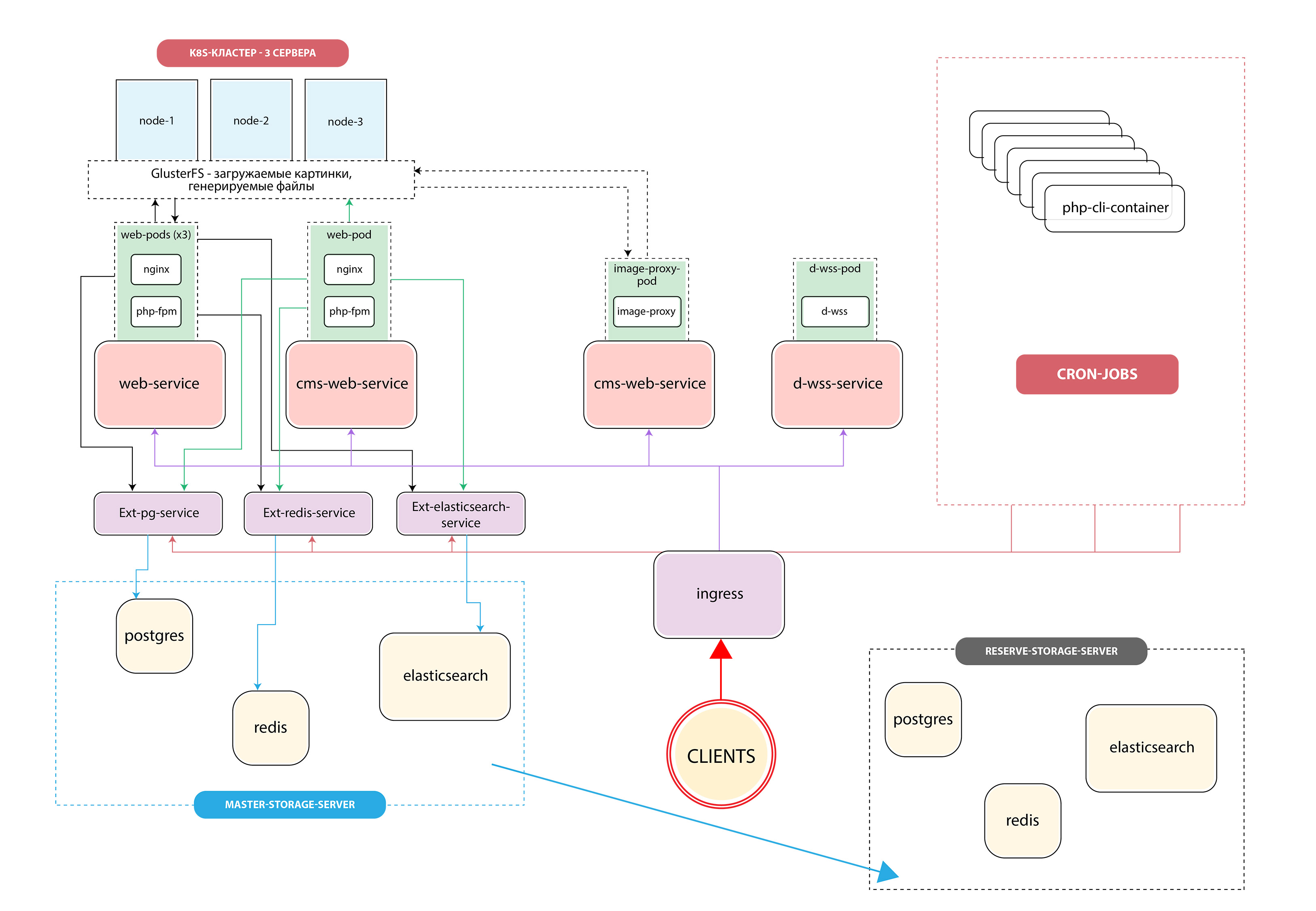
Для работы с файлами первой итерацией мы сделали общую директорию, которая синхронизировалась на все рабочие машины. Под словом «синхронизировалась» я тут подразумеваю именно то, о чём с ужасом можно подумать в первую очередь — rsync по кругу. Очевидно неудачное решение. В итоге всё дисковое пространство мы завели на GlusterFS, настроили работу с картинками так, что они всегда были доступны с любой машины и ничего не тормозило. Для взаимодействия наших приложений с системами хранения данных (postgres, elasticsearch, redis) в k8s были созданы ExternalName-сервисы, чтобы в случае, например, срочного переключения на резервную базу данных обновить параметры подключения в одном месте.
Всю работу с cron’ами вынесли в новые сущности k8s — cronjob, которые умеют запускаться по определённому расписанию.
В итоге мы получили такую архитектуру:
О трудном
Это был запуск первой версии, потому что параллельно с полным перестроением инфраструктуры сайт ещё проходил редизайн. Часть сайта собиралась с одними параметрами — для статики и всего остального, а часть — с другими. Там приходилось… как бы помягче сказать… извращаться со всеми этими multistage-контейнерами, копировать данные из них в разном порядке и т.д.
Также нам пришлось потанцевать с бубнами вокруг CI\CD системы, чтобы научить всё это деплоить и контроллить с разных репозиториев и из разных окружений. Ведь нужен постоянный контроль над версиями приложений, чтобы можно было понять, когда произошёл деплой того или иного сервиса и с какой версии приложения начались те или иные ошибки. Для этого мы наладили правильную систему логирования (а также саму культуру ведения логов) и внедрили ELK. Коллеги научились ставить определённые селекторы, смотреть, какой cron генерирует какие ошибки, как он вообще выполняется, ведь в «кубике» после того, как cron-контейнер выполнился, ты в него больше не попадёшь.
Но самым сложным для нас было переработать и пересмотреть всю кодовую базу.
Напомню, Republic — это проект, которому нынче исполняется 10 лет. Начинался он одной командой, сейчас развивается другой, и перелопатить все-все исходники на предмет возможных багов и ошибок реально сложно. Конечно, в этот момент наш десант из четырех человек подключил ресурсы остальной команды: мы прокликивали и прогоняли тестами весь сайт, даже в тех разделах, которые живые люди не посещали с 2016 года.
Без фейлов никуда
В понедельник, ранним утром, когда людям пошла массовая рассылка с дайджестом, у нас всё встало колом. Виновник нашёлся довольно быстро: запустился cronjob и начал люто-бешено слать письма всем желающим получить подборку новостей за прошедшую неделю, сожрав попутно ресурсы всего кластера. С подобным поведением мы смириться не могли, так что мы быстро проставили жёсткие лимиты на все ресурсы: сколько процессора и памяти может жрать потреблять контейнер и так далее.
Как справлялась команда девелоперов Republic
Изменений наша деятельность принесла немало, и мы это понимали. По сути, мы не только перекроили инфраструктуру издания, вместо привычной связки «основной-резервный сервер» внедрив контейнерное решение, которое по мере необходимости подключает дополнительные ресурсы, но и полностью изменили подход к дальнейшей разработке.
Спустя некоторое время ребята начали понимать, что это не напрямую работа с кодом, а работа с абстрактным приложением. Учитывая процессы CI\CD (построенные на Jenkins), они начали писать тесты, у них появились полноценные dev-stage-prod-окружения, где они могут в реальном времени тестировать новые версии своего приложения, смотреть, где что отваливается, и учиться жить в новом идеальном мире.
Что получил клиент
Прежде всего, Republic наконец-то получил контролируемый процесс деплоя! Раньше как происходило: в Republic был ответственный человек, который шёл на сервер, запускал всё вручную, затем собирал статику, проверял руками, что ничего не отвалилось… Сейчас процесс деплоя выстроен так, что разработчики занимаются именно разработкой и не тратят время ни на что другое. Да и у ответственного теперь одна задача — следить за тем, как прошёл релиз в общем.
После того, как происходит пуш в мастер-ветку, либо автоматически, либо деплоем «по кнопке» (периодически из-за определенных бизнесовых требований автоматический деплой отключается), в бой вступает Jenkins: начинается сборка проекта. Первым делом собираются все docker-контейнеры: в подготовительных контейнерах устанавливаются зависимости (composer, yarn, npm), что позволяет ускорить процесс сборки, если при деплое список необходимых библиотек не изменился; затем собираются контейнеры для php-fpm, nginx, остальных сервисов, в которые, по аналогии с docker-compose окружением, копируются только нужные части кодовой базы. После этого запускаются тесты и, в случае успешного прохождения тестов, происходит пуш образов в приватное хранилище и, собственно, раскатка деплойментов в кубере.
Благодаря переводу Republic на k8s мы получили архитектуру, использующую кластер из трёх реальных машин, на которых может одновременно «крутиться» до двенадцати копий веб-приложения. При этом система сама, исходя из текущих нагрузок, решает, сколько копий ей нужно прямо сейчас. Мы увели Republic от лотереи «работает – не работает» со статичными основным и резервным сервером и построили для них гибкую систему, готовую к лавинообразному росту нагрузки на сайт.
В этот момент может возникнуть вопрос «ребята, вы сменили две железки на те же железки, но с виртуализацией, какой выигрыш, вы там вообще в порядке?» И, конечно, он будет закономерен. Но лишь отчасти. По итогу мы получили не просто железки с виртуализацией. Мы получили стабилизированное рабочее окружение, одинаковое как в проде, так и на деве. Окружение, которое управляется централизованно для всех участников проекта. Мы получили механизм сборки всего проекта и выкатки релизов, опять же, единый для всех. Мы получили удобную систему оркестрации проекта. Как только команда Republic заметит, что им в целом перестаёт хватать текущих ресурсов и риски сверхвысоких нагрузок (либо когда уже стряслось и всё легло), они просто берут ещё один сервер, за 10 минут раскатывают на нём роль узла кластера, и оп-оп — всё снова красиво и хорошо. Предыдущая же структура проекта вообще не предполагала такого подхода, там не было ни медленных, ни быстрых решений подобных проблем.
Во-вторых, появился бесшовный деплой: посетитель либо попадёт на старую версию приложения, либо на новую. А не как раньше, когда контент мог быть новый, а стили старые.
В итоге, бизнес доволен: всякие новые вещи теперь можно делать быстрее и чаще.
Суммарно от «а давайте попробуем» до «готово» работа над проектом заняла 2 месяца. Команда с нашей стороны — героический десант в четыре человека + поддержка «базы» на время проверки кода и тестов.
Что получили пользователи
А посетители, в принципе, изменений не увидели. Процесс деплоя на стратегии RollingUpdate построен «бесшовным». Выкатывание новой версии сайта НИКАК не задевает пользователей, новая версия сайта, пока не пройдут тесты и liveness/readiness пробы, не будет доступна. Они просто видят, что сайт работает и вроде не собирается падать после публикации крутых статей. Что, в общем-то, и нужно любому проекту.


