
Инфраструктура еды: как мы саппортим «Тануки»
2 года назад мы приняли на поддержку одну из крупнейших сетей доставки еды — «Тануки». Месячная аудитория сайта — порядка миллиона человек. Это теперь, в 2020 году. В 2018-м, когда «Тануки» начали сотрудничество с нами, она была в 2 раза меньше. Мы обеспечили безболезненный переезд в новый дата-центр и полностью переделали инфраструктуру — благодаря чему, собственно, сайт и приложения способны без проблем выдерживать возросшую нагрузку. И теперь хотим рассказать вам историю саппорта одного из крупнейших веб-проектов отечественной «индустрии гостеприимства».
Перефразируя одного известного исторического деятеля, важнейшим из всех сервисов для нас является доставка. Что бы мы делали в нынешней ситуации без роллов или пиццы на дом — представлять не хочется. Так получилось, что 2 года назад мы приняли на поддержку одну из крупнейших сетей — «Тануки». Актуальная месячная аудитория сайта — порядка миллиона человек.
Временами мы сильно жалеем, что географически находимся далековато от ближайшего ресторана «Тануки»: иначе все свои успехи (и маленькие незадачи) заедали бы вкусными роллами.
В общем, сегодня мы хотим рассказать вам историю саппорта одного из крупнейших веб-проектов отечественной «индустрии гостеприимства».
Итак, мы познакомились в конце марта 2018-го. Международный женский день давно прошел, но ребята только-только справились с его последствиями. Всё довольно банально: накануне 8 марта трафик резко вырос, и сайт долгое время был недоступен. По-настоящему долгое, а не пару часов. Потому что трафик летел не только через основной сайт, но и поступал из приложения (есть для Android и iOS), а также агрегаторов («Яндекс. Еда», «Деливери Клаб», «Зака-зака»).
Что мы увидели
Технически проект оказался достаточно сложным:
- Сайт — react-приложение с SSR (server side rendering).
- Мобильные приложения — для iOS / Android.
- API — с ним работают все приложения.
- Внешние системы, в том числе, обработки заказов.
Система представляла собой серверы реверс-прокси: трафик на них шел через систему защиты от DDoS-атак и оттуда уже распределялся по бэкенд-серверам. На момент приемки был старый сайт и API для мобильных версий и стартовала разработка нового сайта. Разработка нового API велась на отдельных серверах.
Кластер БД представлял собой два сервера с мастер/мастер репликацией, где переключение в случае сбоя производилось на сетевом уровне за счет плавающего IP. Все приложения на запись работали с этим IP, в то время как на чтение были слейвы MySQL, размещенные на каждом сервере бэкенда — где приложение, соответственно, работало с localhost.
На приёмке мы увидели следующие проблемы:
- Недостаточно надежный механизм балансировки в конфигурации БД. Мастер-мастер репликации приводили к частым сбоям.
- Слейвы на каждом бэкенде — требовали большой объем дискового пространства. А любые манипуляции или добавление новых бэкенд-серверов требовали больших затрат.
- Не было общей системы деплоя приложений — была самописная система деплоя через веб.
- Не было системы сбора логов — вследствие чего достаточно сложно расследовать инциденты, в первую очередь, в работе с системой заказов, поскольку нет возможности определить, как был принят тот или иной заказ.
- Отсутствовал мониторинг бизнес-показателей — не было возможности своевременно фиксировать снижение или полное отсутствие заказов.
После первичного аудита принятых на мониторинг серверов мы начали с формирования оперативного роадмапа. Изначально выделили два основных направления работ:
- Стабилизация работы приложений.
- Организация комфортной среды разработки для нового API и сайта.
Решения по первому направлению были, прежде всего, связаны со стабилизацией работы кластера MySQL. Отказываться от мастер-мастер репликации не хотелось, но и продолжать работать с плавающим IP было невозможно. Периодически наблюдались нарушения сетевой связанности, что приводило к нарушениям работы кластера.
Прежде всего, мы решили отказаться от плавающего IP в пользу прокси-сервера, где между мастерами будет контролируемо переключаться апстрим, так как в качестве прокси для MySQL мы задействовали nginx. Второй шаг — выделение двух отдельных серверов под слейвы. Работа с ними была также организована через прокси-сервер. И с момента реорганизации мы забыли о проблемах, связанных с работой с БД.
Далее мы замониторили заказы на уровне запросов в БД. Любое отклонение от нормы — в меньшую или большую сторону — сразу давало повод для начала расследования. Затем, на уровне логов, мы сформировали метрики для мониторинга внешних взаимодействий, в частности, с системой управления заказами.
Совместно с коллегами, по их запросам, производили донастройку всех систем до стабильной и быстрой работы. Это был и тюнинг MySQL, и обновление версий PHP. Кроме того, коллеги внедряли систему кэширования на базе Redis, что также способствовало снижению нагрузки на БД.
Все это было важно… Но главное для бизнеса — увеличение продаж. И в этом контексте большие надежды менеджеры компании возлагали на новый сайт. Для разработчиков же было необходимо получить стабильную и удобную систему для деплоя и контроля приложения.
В первую очередь, мы задумывались о конвейерах сборки и доставки приложения CI/CD, а также системах сбора и работы с логами.
Все репозитории клиента были размещены на self-hosted bitbucket-решении. Для организации пайплайнов был выбран jenkins.
Для начала пайплайны было принято внедрить на дев-окружениях — это позволило значительно увеличить скорость разработки. Затем это было внедрено и на продакшн-контурах, где автоматический деплой позволил избежать частых ошибок, как правило, вызываемых человеческим фактором.
После внедрения CI/CD занялись организацией сбора логов и работы с ними. В качестве основного был выбран стек ELK, что позволило клиенту быстрее и качественнее проводить расследования в случае наступления инцидентов. И как результат — разработка приложения пошла быстрее.
«Страшнее двух пожаров…»
После решения достаточно сложных, но, тем не менее, стандартных задач, «Тануки» сказали нам то, что давно хотели сказать: «А давайте переедем!»
Смена ДЦ была вызвана экономическими факторами. Кроме того, клиент расширял свою инфраструктуру за счет дополнительных сервисов, которые уже были в новом ДЦ, — это также повлияло на принятие решения о переезде.
Миграция любой системы, а тем более, сложной — это процесс, требующий обстоятельного планирования и больших ресурсов.
Переезд проводился итерационно: на первом этапе были созданы реверс-прокси серверы в новом ДЦ. И поскольку только они обладают public ip — они же выступали и в качестве точек доступа в систему для администраторов.
Затем мы запустили все инфраструктурные сервисы — логирование и CI/CD. А Consul позволил организовать удобный, управляемый и достаточно надежный сервис взаимодействия между приложениями клиента.
Следующими мигрировали БД, Redis и брокер очередей — RabbitMQ. Тут было важно организовать всё так, чтобы они корректно регистрировались в протоколе обнаружения сервисов, который, в свою очередь, управлял работой ДНС. Отметим, что приложения работали не напрямую с БД, а через Haproxy, который позволяет удобно и балансировать между базами и переключаться в случае отказа.
На подготовительном этапе репликация БД между дата-центрами не поднималась. Пришлось просто перенести бэкапы. Следом начали настройку непосредственно приложений, а это организация всего взаимодействия через внутренний DNS — взаимодействия между приложением и БД/Redis/RabbitMQ/внешними сервисами (например, сервисами заказа). Естественно, на этом же этапе сразу подключались все механизмы CI/CD — и тут возникло второе изменение в архитектуре. Ранее менять настройки приложения через интерфейс возможности не было — только через редактирование файлов непосредственно в консоли. Тут же мы внедрили решение, позволяющее удобно управлять настройками — через веб интерфейс. Оно было основано на Hashicorp vault (в качестве бэкенда для него выступил Consul), что позволило построить удобные механизмы управления переменными окружения.
Следующий шаг — переключение сервисов на новый ДЦ. Поскольку работа всех систем организована по протоколу http, а все домены шли через систему защиты от DDoS-атак, то переключение сводилось к манипуляциям с апстримами непосредственно в интерфейсе этой системы.
Предварительно были организованы необходимые реплики из старого ДЦ в новый. И в согласованное окно работ было произведено переключение.
Как инфраструктура выглядит сейчас:
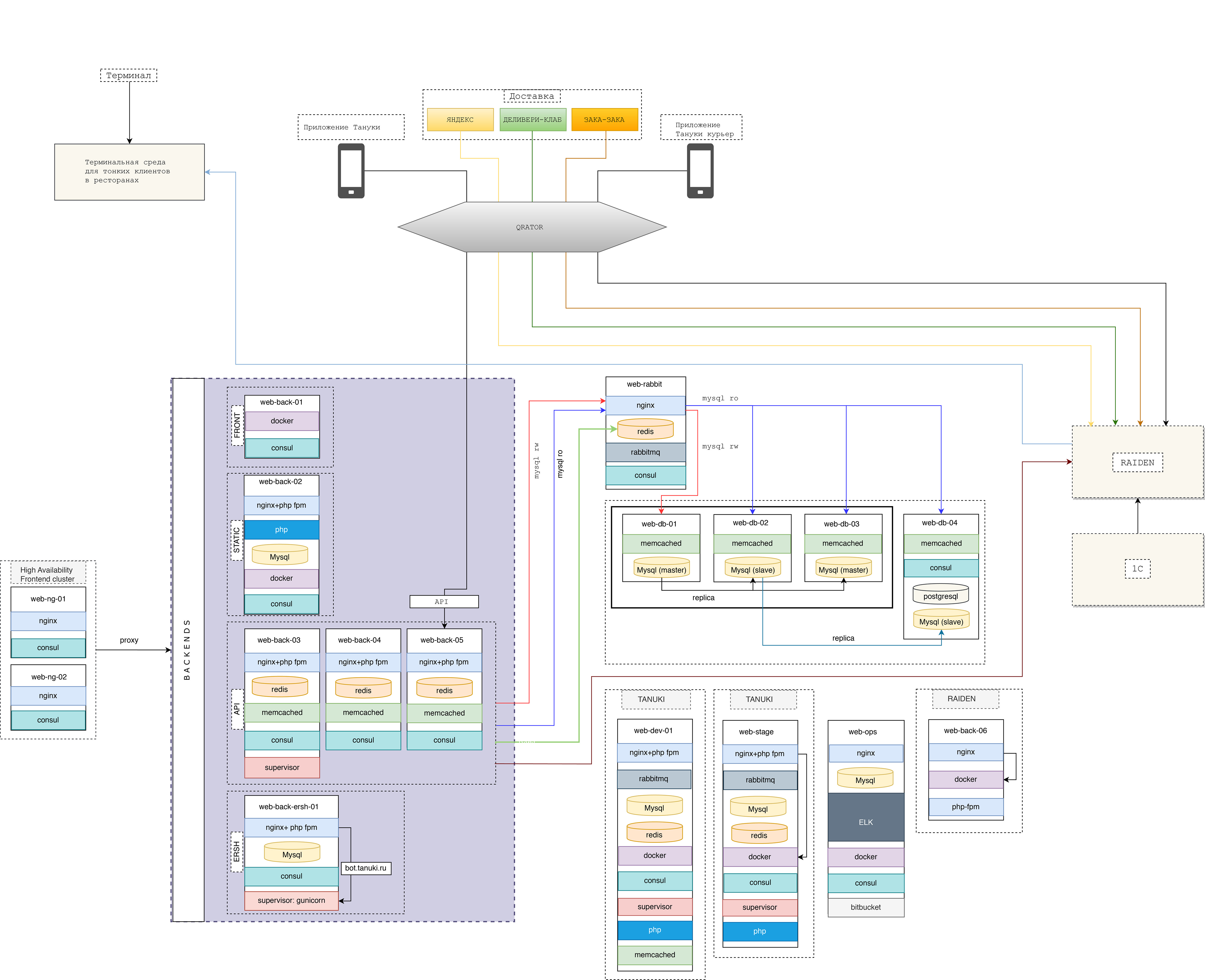
- Весь трафик поступает на балансеры. Трафик до API идет с приложения Тануки (на Android/iOS) не напрямую, а через Qrator.
- На static сервере находится основной сайт проекта tanuki.ru, сервер с лендингами.
- Кластер бэкенда сейчас состоит из серверов: фронтенд, статика, серверов под приложения.
Что изменилось для заказчика
- Надежность системы: проблемы наблюдались в июле 2019-го — заказы не оформлялись в течение часа. Но это было до глобального переезда. В дальнейшем крупных инцидентов не наблюдалось.
- Жизнь разработчиков: у них появилась удобная среда разработки, CI/CD.
- Отказоустойчивость: инфраструктура сейчас выдерживает большой трафик. Например, в праздничные дни RPS достиг пика в 550 единиц.
Что дальше
В современных условиях онлайн-продажи выходят на первый план. Проект должен обеспечивать надежность и доступность для клиентов сервиса. Но и развитие — тоже очень важный компонент: релизы продукта должны быть максимально быстрыми и незаметными для конечных пользователей.
Ещё один важный вопрос — это утилизация ресурсов и снижение затрат на содержание системы.
Всё это ведёт к необходимости пересмотра системы в целом. Первым шагом будет организация контейнеризации приложений. Затем планируется организация кластера Kubernetes. Но об этом мы расскажем в следующей статье. А пока — приятного аппетита :-)


