
Как мы тестировали несколько баз данных временных рядов
Может показаться, что в 2019-м году статья про то, какую TSDB стоит использовать, будет состоять лишь из одного предложения: «просто используйте ClickHouse». Но… есть нюансы.
За последние несколько лет базы данных временных рядов (Time-series databases) превратились из диковинной штуки (узкоспециализированно применяющейся либо в открытых системах мониторинга (и привязанной к конкретным решениям), либо в Big Data проектах) в «товар народного потребления». На территории РФ отдельное спасибо за это надо сказать Яндексу и ClickHouse’у. До этого момента, если вам было необходимо сохранить большое количество time-series данных, приходилось либо смириться с необходимостью поднять монструозный Hadoop-стэк и сопровождать его, либо общаться с протоколами, индивидуальными для каждый системы.
Может показаться, что в 2019-м году статья про то, какую TSDB стоит использовать, будет состоять лишь из одного предложения: «просто используйте ClickHouse». Но… есть нюансы.
Действительно, ClickHouse активно развивается, пользовательская база растет, а поддержка ведется очень активно, но не стали ли мы заложниками публичной успешности ClickHouse'а, которая затмила другие, возможно, более эффективные/надежные решения?
В начале прошлого года мы занялись переработкой нашей собственной системы мониторинга, в процессе которой встал вопрос о выборе подходящей базы для хранения данных. Об истории этого выбора я и хочу здесь рассказать.
Постановка задачи
Прежде всего — необходимое предисловие. Зачем нам вообще собственная система мониторинга и как она была устроена?
Мы начали оказывать услуги поддержки в 2008 году, и к 2010-му стало понятно, что агрегировать данные о происходящих в клиентской инфраструктуре процессах решениями, существовавшими на тот момент, стало сложно (мы говорим о, прости господи, Cacti, Zabbix-е и зарождающемся Graphite).
Основными нашими требованиями были:
- сопровождение (на тот момент — десятков, а в перспективе — сотен) клиентов в пределах одной системы и при этом наличие централизованной системы управления оповещениями;
- гибкость в управлении системой оповещений (эскалация оповещений между дежурными, учет расписания, база знаний);
- возможность глубокой детализации графиков (Zabbix на тот момент отрисовывал графики в виде картинок);
- длительное хранение большого количества данных (год и более) и возможность их быстрой выборки.
В данной статье нас интересует последний пункт.
Говоря о хранилище, требования были следующие:
- система должна быстро работать;
- желательно, чтобы система имела SQL-интерфейс;
- система должна быть стабильной и иметь активную пользовательскую базу и поддержку (когда-то мы столкнулись с необходимостью поддерживать такие системы, как например MemcacheDB, которую перестали развивать, или распределенное хранилище MooseFS, багтрекер которого велся на китайском языке: повторения этой истории для своего проекта нам не хотелось);
- соответствие CAP-теореме: Consitency (необходимо) — данные должны быть актуальными, мы не хотим, чтобы система управления оповещениями не получила новых данных и плюнулась алертами о неприходе данных по всем проектам; Partition Tolerance (необходимо) — мы не хотим получить Split Brain системы; Availability (не критично, в случае существования активной реплики) — можем сами переключиться на резервную систему в случае аварии, кодом.
Как ни странно, на тот момент идеальным решением для нас оказался MySQL. Наша структура данных была предельно проста: id сервера, id счетчика, timestamp и значение; быстрая выборка горячих данных обеспечивалась большим размером buffer pool, а выборка исторических данных — SSD.
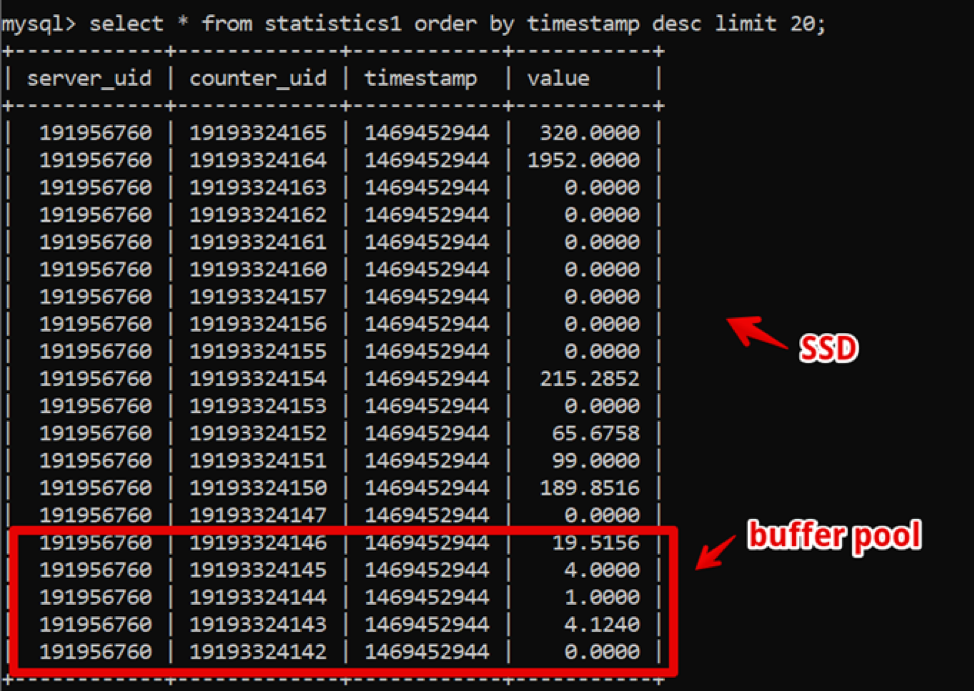
Таким образом, мы добились выборки свежих двухнедельных данных, с детализацией до секунды за 200 мс до момента полной отрисовки данных, и жили в этой системе довольно долго.
Между тем, время шло и количество данных росло. К 2016-му году объемы данных достигали десятков терабайт, что в условиях арендуемых SSD-хранилищ было существенным расходом.
К этому моменту активное распространение получили колоночные базы данных, о которых мы стали активно думать: в колоночных БД данные хранятся, как это можно понять, колонками, и если посмотреть на наши данные, то легко увидеть большое количество дублей, которые можно было бы, в случае использовании колоночной БД, сжать компрессией.
Однако ключевая для работы компании система продолжала работать стабильно, и экспериментировать с переходом на что-то другое не хотелось.
В 2017-м году на конференции Percona Live в Сан-Хосе, наверное, впервые о себе заявили разработчики Clickhouse. На первый взгляд, система была production-ready (ну, Яндекс.Метрика — это суровый продакшн), поддержка была быстрой и простой, и, главное, эксплуатация была простой. С 2018-го года мы затеяли процесс перехода. Но к тому времени «взрослых» и проверенных временем систем TSDB стало много, и мы решили выделить значительное время и сравнить альтернативы, для того чтобы убедиться, что альтернативных Clickhouse-у решений, согласно нашим требованиям, нет.
В дополнении к уже указанным требованиям к хранилищу появились свежие:
- новая система должна обеспечивать, как минимум, такую же производительность, что и MySQL, на том же самом количестве железа;
- хранилище новой системы должно занимать значительно меньше места;
- СУБД по-прежнему должна быть проста в управлении;
- хотелось минимально менять приложение при смене СУБД.
Какие системы мы стали рассматривать
Apache Hive/Apache Impala
Старый проверенный боями Hadoop-стэк. По сути, это SQL-интерфейс, построенный поверх хранения данных в собственных форматах на HDFS.
Плюсы:
- При стабильной эксплуатации очень просто масштабировать данные.
- Есть колоночные решения по хранению данных (меньше места).
- Очень быстрое выполнение распаралелленых задач при наличии ресурсов.
Минусы:
- Это Hadoop, и он сложен в эксплуатации. Если мы не готовы брать готовое решение в облаке (а мы не готовы по стоимости), весь стэк придется собирать и поддерживать руками админов, а этого очень не хочется.
- Данные агрегируются действительно быстро.
Однако:

Скорость достигается масштабированием числа вычислительных серверов. Проще говоря, если мы большая компания, занимаемся аналитикой и бизнесу критически важно максимально быстро агрегировать информацию (пусть даже ценой использования большого количества вычислительных ресурсов), — это может быть нашим выбором. Но мы не были готовы кратно увеличивать парк железа для скорости выполнения задач.
Druid/Pinot
Уже гораздо больше про конкретно TSDB, однако опять же — Hadoop-стэк. Есть отличная статья, сравнивающая плюсы и минусы Druid и Pinot в сравнении с ClickHouse .
Если в нескольких словах: Druid/Pinot выглядят лучше Clickhouse'а в случаях, когда:
- У вас гетерогенный характер данных (в нашем случае мы записываем только таймсерии серверных метрик, и, по сути, это одна таблица. Но могут быть и другие кейсы: временные ряды оборудования, экономические временные ряды и т.д. — каждый со своей структурой, которые надо агрегировать и обрабатывать).
- При этом этих данных очень много.
- Таблицы и данные с временными рядами появляются и пропадают (то есть какой-то набор данных пришел, его проанализировали и удалили).
- Нет четкого критерия, по которому данные могут быть партиционированы.
В противоположных случаях лучше себя показывает ClickHouse, а это наш случай.
ClickHouse
- SQL-like.
- Прост в управлении.
- Люди говорят, что он работает.
Попадает в шорт-лист тестирования.
InfluxDB
Зарубежная альтернатива ClickHouse'у. Из минусов: High Availability присутствует только в коммерческой версии, но надо сравнить.
Попадает в шорт-лист тестирования.
Cassandra
С одной стороны, мы знаем, что ее используют для хранения метрических таймсерий такие системы мониторинга, как, например, SignalFX или OkMeter. Однако есть специфика.
Cassandra не является колоночной базой данных в привычном ее понимании. Выглядит она больше как строчная, но в каждой строке может быть разное количество столбцов, за счет чего легко организовать колоночное представление. В этом смысле понятно, что при ограничении в 2 миллиарда столбцов можно хранить какие-то данные именно в столбцах (да те же временные ряды). Например, в MySQL стоит ограничение на 4096 столбцов и там легко наткнуться на ошибку с кодом 1117, если попытаться сделать тоже самое.
Движок Cassandra ориентирован на хранение больших объемов данных в распределенной системе без мастера, и в вышеупомянутой CAP-теореме Cassandra больше про AP, то есть про доступность данных и устойчивость к разделению партиций. Таким образом, этот инструмент может замечательно подойти, если нужно только писать в эту базу и достаточно редко из нее читать. И тут логично использовать Cassandra в качестве “холодного” хранилища. То есть в качестве долговременного надежного места хранения больших массивов исторических данных, которые редко требуются, но при необходимости их можно достать. Тем не менее, ради полноты картины, протестируем и ее. Но, как я ранее говорил, нет желания активно переписывать код под выбранное БД-решение, поэтому тестировать мы её будем несколько ограничено — без адаптации структуры базы под специфику Cassandra.
Prometheus
Ну, и уже из интереса мы решили протестировать производительность стораджа Prometheus — просто для того, чтобы понять, быстрее мы текущих решений или медленнее и насколько.
Методика и результаты тестирования
Итак, мы протестировали 5 баз данных в следующих 6 конфигурациях: ClickHouse (1 нода), ClickHouse (распределенная таблица на 3 ноды), InfluxDB, Mysql 8, Cassandra (3 ноды) и Prometheus. План тестирования такой:
- заливаем исторические данные за неделю (840 млн значений в сутки; 208 тысяч метрик);
- генерируем нагрузку на запись (рассматривали 6 режимов нагрузки, см. ниже);
- параллельно с записью периодически делаем выборки, эмулируя запросы пользователя, работающего с графиками. Чтобы не слишком усложнять, выбирали данные по 10 метрикам (как раз столько их на графике CPU) за неделю.
Нагружаем, эмулируя поведение агента нашего мониторинга, который отправляет в каждую метрику значения раз в 15 секунд. При этом нам интересно варьировать:
- общее количество метрик, в которые пишутся данные;
- интервал отправки значений в одну метрику;
- размер батча.
Про размер батча. Поскольку почти все наши подопытные базы не рекомендуется нагружать единичными инсертами, нам нужен будет релей, который собирает приходящие метрики и группирует их по сколько-нибудь и пишет в базу пакетным инсертом.
Также, чтобы лучше понимать, как потом интерпретировать полученные данные, представим, что мы не просто шлём кучу метрик, а метрики организованы в серверы — по 125 метрик на сервер. Тут сервер просто виртуальная сущность — просто чтобы понимать, что, например, 10000 метрик соответствуют примерно 80 серверам.
И вот, с учетом этого всего, наши 6 режимов нагрузки базы на запись:
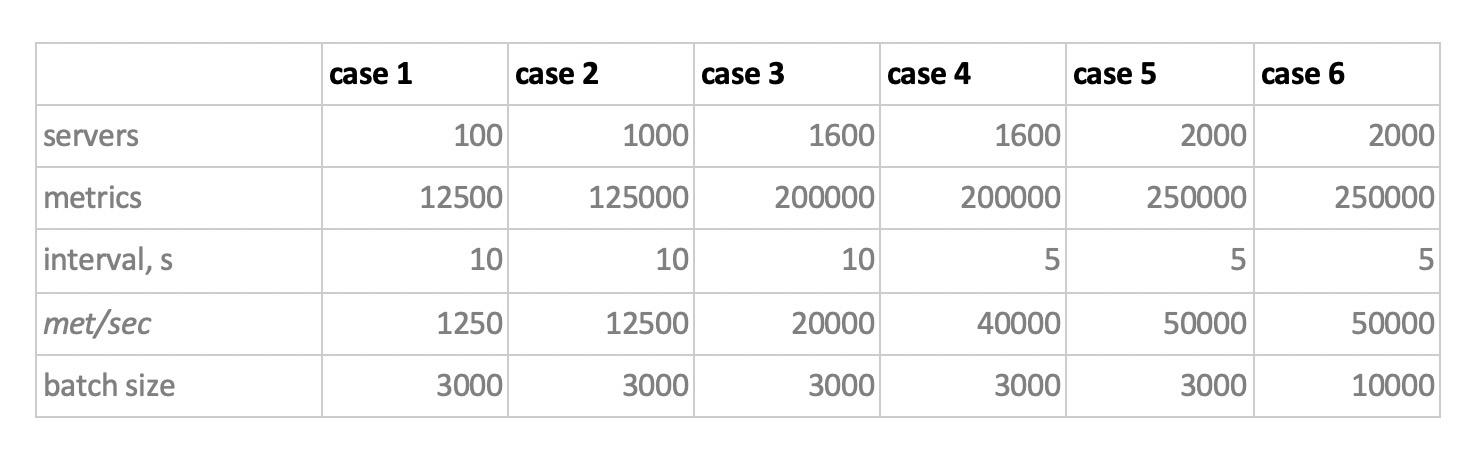
Тут есть два момента. Во-первых, для кассандры такие размеры батчей оказались слишком большими, там мы использовали значения 50 или 100. А во-вторых, поскольку прометеус работает строго в режиме pull, т.е. сам ходит и забирает данные с источников метрик (и даже pushgateway, несмотря на название, в корне ситуацию не меняет), соответствующие нагрузки были реализованы с помощью комбинации static configs.
Результаты тестирования такие:
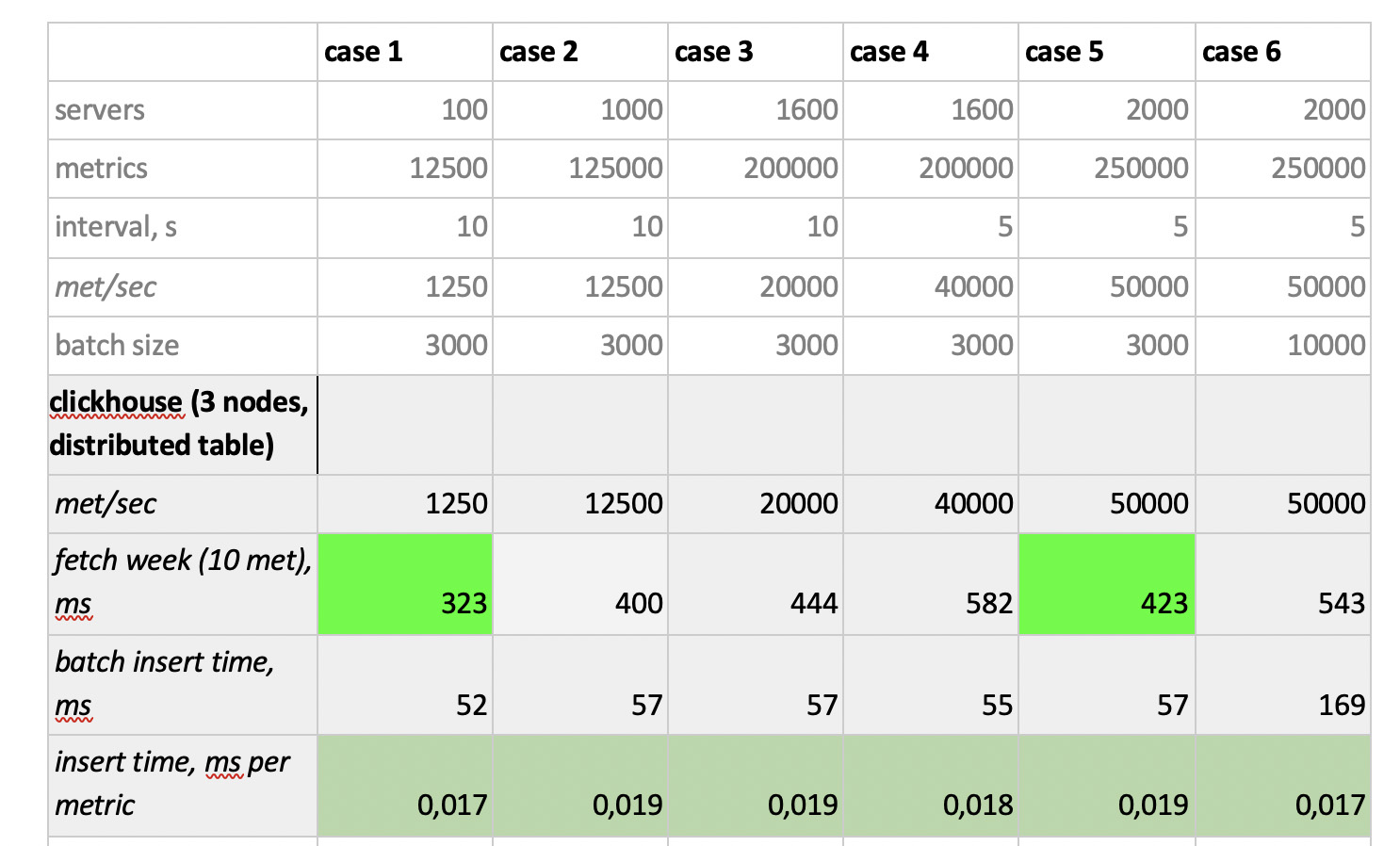
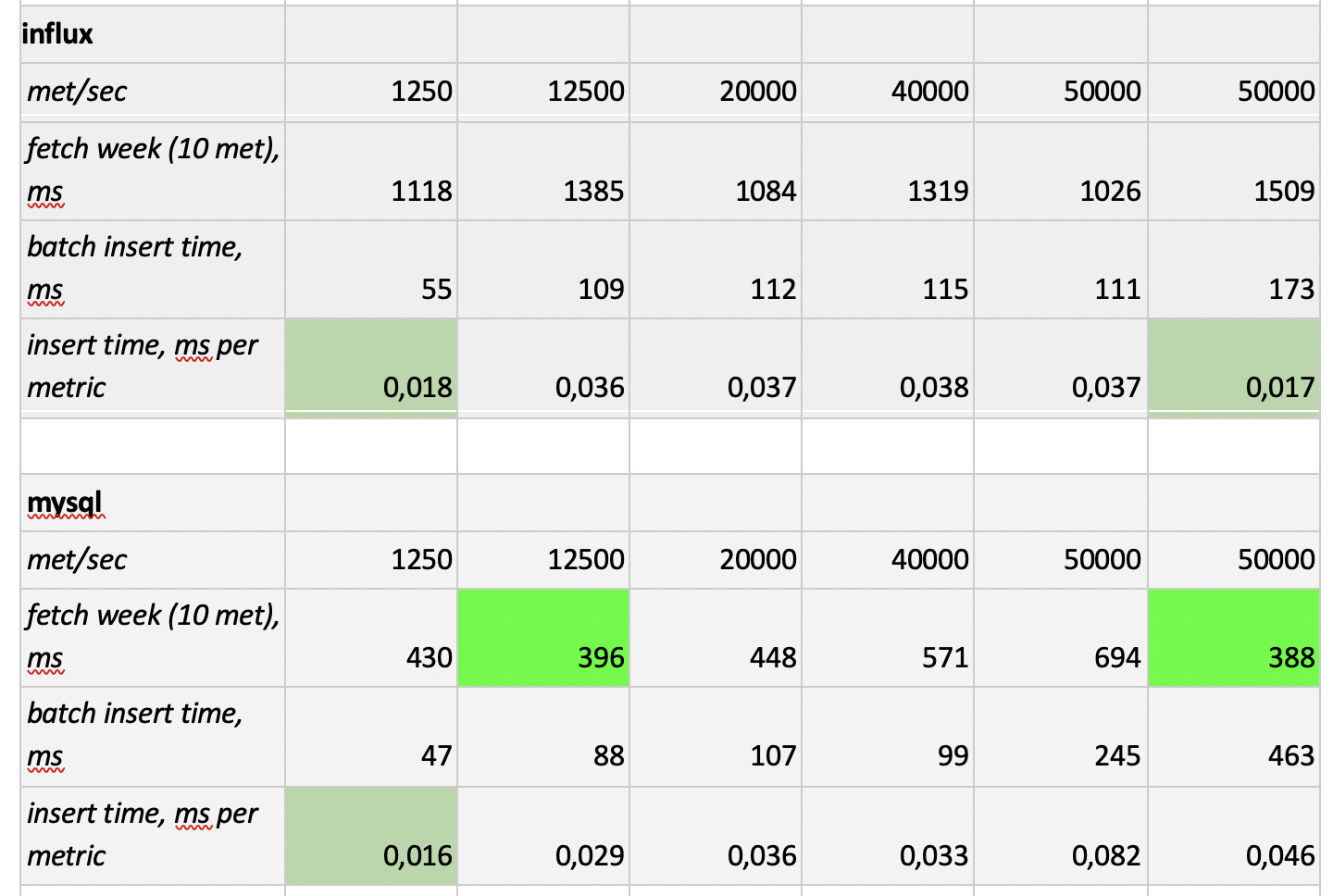
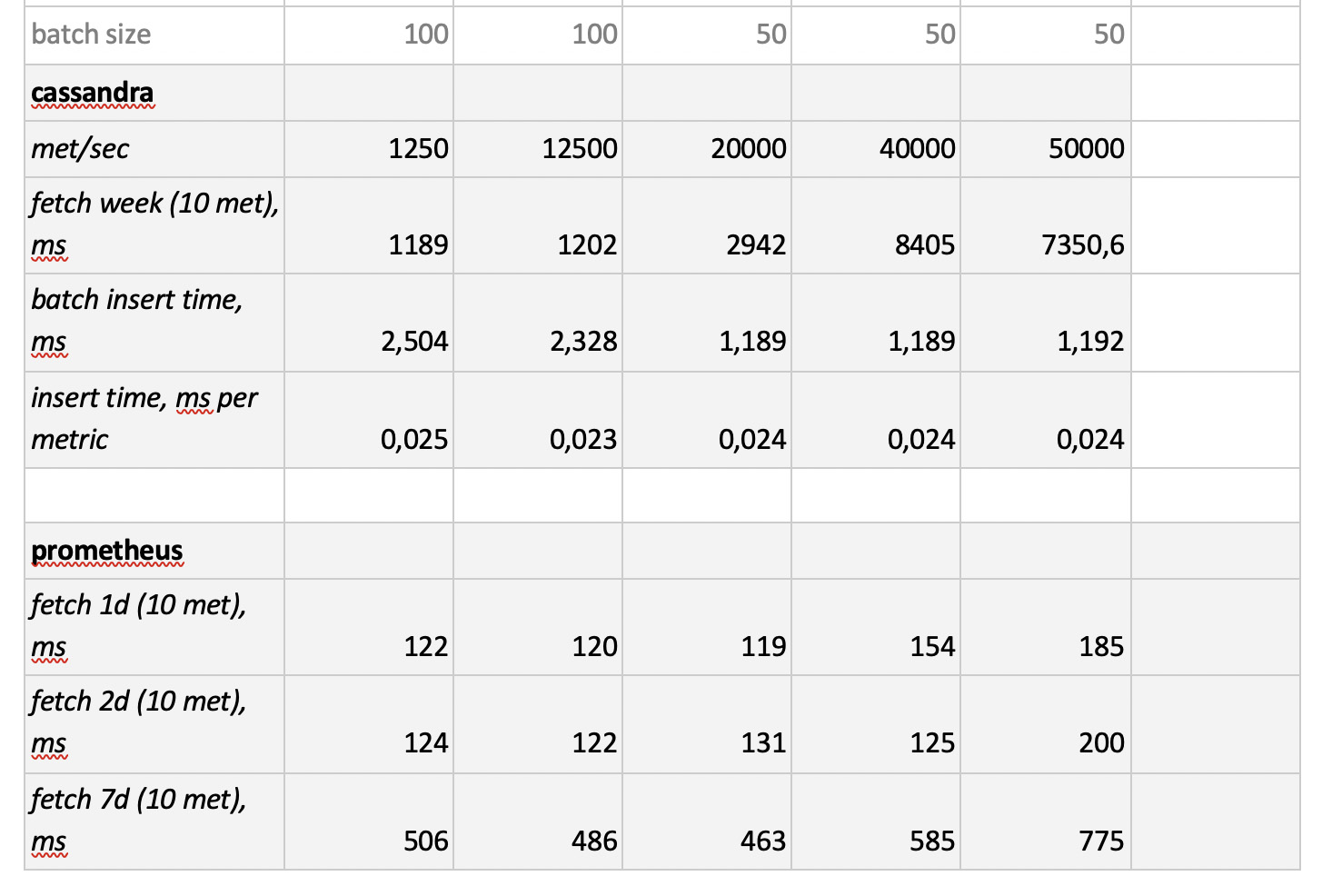 Что стоит отметить: фантастически быстрые выборки из Prometheus'a, ужасающе медленные выборки из Cassandra, неприемлемо медленные выборки из InfluxDB; по скорости записи всех победил ClickHouse, а Prometheus в конкурсе не участвует, потому что он делает инсерты сам внутри себя и мы ничего не замеряем.
Что стоит отметить: фантастически быстрые выборки из Prometheus'a, ужасающе медленные выборки из Cassandra, неприемлемо медленные выборки из InfluxDB; по скорости записи всех победил ClickHouse, а Prometheus в конкурсе не участвует, потому что он делает инсерты сам внутри себя и мы ничего не замеряем.
В итоге: лучше всех себя показали ClickHouse и InfluxDB, но кластер из Influx’а можно построить только на основе Enterprise-версии, которая стоит денег, а ClickHouse ничего не стоит и сделан в России. Логично, что в США выбор, пожалуй, в пользу inInfluxDB, а у нас — в пользу ClickHouse'а.




