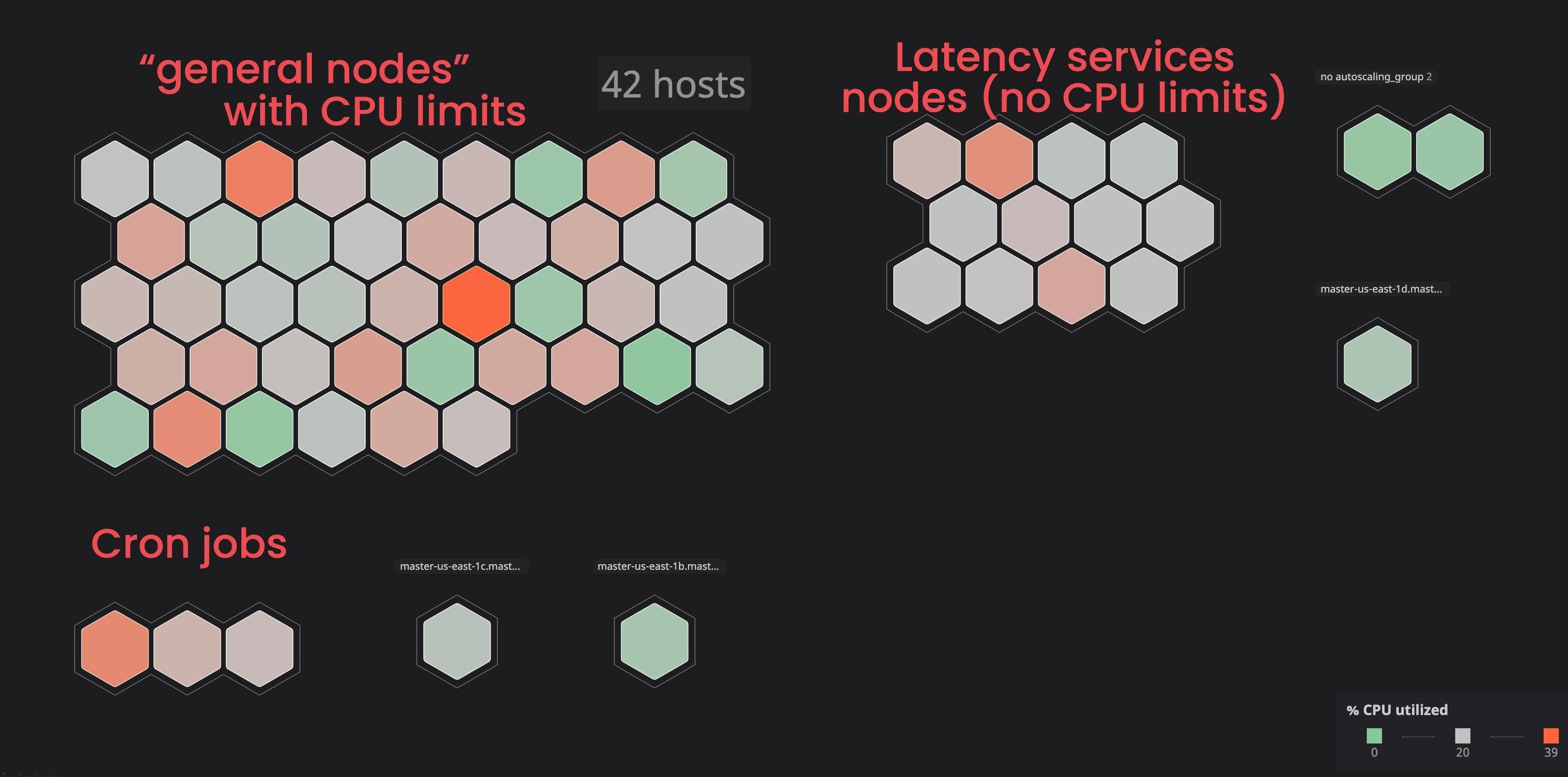
Найти предел: в чём смысл нагрузочного тестирования IT-инфраструктуры
Хотите, чтобы ваш стартап или IT-проект вырос? Чтобы вашим сайтом пользовалось больше людей и прибыль росла? Но справятся ли ваши серверы, сервисы, базы данных? В статье разбираемся, как найти, куда подложить соломку, чтобы выдержать нагрузку.
Работа приложений и сайтов обычно зависит от того, сколько людей их используют. То, что работало при посещаемости 100 человек в день, может не выдержать, если тысяча человек попробует одновременно воспользоваться сервисом: база данных не сможет с той же скоростью обрабатывать возросшее число запросов, диски могут не справиться с количеством операций чтения-записи, может не хватить оперативной памяти — словом, вариантов негативного сценария хватает. Но развязка для всех одна: если сервис станет работать слишком медленно, то пользователи, не дождавшись результата, начнут уходить. Ну, а если он просто «упадёт», то вы совсем потеряете клиентов. IT-инфраструктура в этом смысле не отличается от любой другой — у неё есть запас прочности и ресурс нагрузки, которую можно выдержать.
Если провести аналогию с грузоперевозками, то каждому понятно, что на легковой курьерской машине не увезти мебель. Или что даже если в открытый кузов маленького грузовичка можно положить 5 тонн кирпича, он всё равно не сможет их увезти. С IT-системами также — и нагрузочное тестирование нужно, чтобы выяснить «максимальную снаряжённую массу». А еще — чтобы понять, где можно потюнить и в итоге, продолжая аналогию, всё же возить больше: переоборудовать салон, поменять подвеску, поставить грузовые шины или просто-напросто по-другому складывать коробки.
Надо просто, чтобы предела не было. Тогда и проблем не будет
Если смотреть с точки зрения заказчика, который покупает услуги разработки, то ожидания, что исполнитель сразу предусмотрит все узкие места и оптимально настроит серверное окружение, вполне понятны. Так же, как и недовольство, если что-то пошло не так. А ещё бывает, что система вроде бы работает, а программисты или админы утверждают: всё нужно переделывать и увеличивать бюджет на инфраструктуру. Как тут не огорчиться?
Однако дело не в том, что инженеры недостаточно компетентны или ленивы (хотя такое, к большому сожалению, тоже случается, поэтому советуем детально обсуждать проект до начала работ, смотреть примеры выполненных проектов и отзывы). Рост пользовательской нагрузки в любом случае требует больших ресурсов, которые всегда конечны.
Есть две основных причины, почему чаще всего нельзя сразу сделать стопроцентно безотказную систему, способную переварить неограниченные нагрузки. Во-первых, это банально вопрос бюджета. Чем больше пользователей, тем больше нужно серверных мощностей и тем дороже это будет стоить. А если вы только начинаете работу и даже не уверены, что проект выстрелит, закупать х100 серверов от того, что пока нужно, не имеет никакого смысла. Да и разрабатывать сервис под все возможные перспективы роста будет сложнее и дольше: перспективнее собрать MVP малыми средствами, проверить рынок и бизнес-гипотезу, а уже потом вкладываться в разработку. Во-вторых, современные приложения устроены так сложно, интегрируют в себе так много компонентов, что человек уже не в состоянии умозрительно предусмотреть все сценарии и предугадать исходы всех сочетаний взаимодействия разных частей сложной системы — нужна комплексная проверка.
Существуют разные виды тестирования, но в этой статье мы не будем обсуждать, как проверить, что все функции сервиса в любых условиях работают. Мы поговорим о следующем этапе — нагрузочном тестировании, которое помогает ответить на важный вопрос: сколько пользователей сейчас могут без проблем воспользоваться нашим продуктом и что нужно сделать, чтобы инфраструктура позволила в будущем качественно обслужить больше клиентов? Причём поговорим больше в терминах бизнес-задач, а технические аспекты рассмотрим в другой раз.
Тестирование на максимальную нагрузку
В IT-терминологии, особенно на русском языке, есть разночтения. Для похожих по целям исследований используют названия и нагрузочного тестирования, и тестирования производительности, и даже стресс-тестирования. Поэтому определим понятия и задачи, исходя из своего опыта; на общность и единственно верную трактовку не претендуем.
С технической точки зрения нагрузочное тестирование отвечает на следующие вопросы:
-
Как система справляется с «нормальным» (регулярным, ожидаемым) уровнем нагрузки, отвечает ли требованиям пользователей по скорости ответа?
-
Как скажется на инфраструктуре длительная эксплуатация, будет ли она работать надёжно в долгосрочной перспективе?
-
Что произойдет при резком скачке нагрузки, как система переживёт пиковую посещаемость?
-
Как система будет себя вести при продолжительной повышенной нагрузке?
-
Какую максимальную нагрузку инфраструктура способна выдержать без деградации и что произойдет при достижении предела?
В терминах бизнес-задач это помогает оценить уровень обслуживания, который получают пользователи в обычной ситуации, узнать, что произойдёт, когда пользователей станет больше, и определить порог посещаемости при текущем состоянии инфраструктуры. Конечно, всё это измерить — дело хорошее, но хотелось бы ещё и выяснить, где слабые места и что нужно исправить, — к этому вопросу вернёмся чуть позже.
Что проверяет нагрузочное тестирование
Как и в любом другом тестировании, в нагрузочном воспроизводят все основные действия пользователей и таким образом проверяют важные для бизнеса сценарии. Для интернет-магазинов это, например, вход в личный кабинет, просмотр и выбор каталогов, добавление товаров в корзину, оформление заказа, оплата. Для СМИ — сёрфинг по новостям, оформление подписки, новостные рассылки и т.д.
Либо, исходя из требований заказчика, в ходе тестирования можно сосредоточиться на каком-то одном элементе системы — том, который наиболее критичен для бизнеса, или том, который выглядит самым узким местом. Это также может быть оформление заказа или, например, регистрация и авторизация пользователей. Вход на сайт часто необходим для полноценной работы с сервисом и при этом легко оказывается бутылочным горлышком — так, например, было у «Тотального диктанта» (о том, как готовили сайт «Тотального диктанта» к нагрузке карантинного 2021-го, смотрите в отдельной статье).
Проводя тестирование производительности, мы имитируем множество одновременных вышеперечисленных стандартных действий с сайтом. Сначала постепенно увеличиваем нагрузку с самых низких значений, чтобы примерно определить максимум и позже его уточнить.
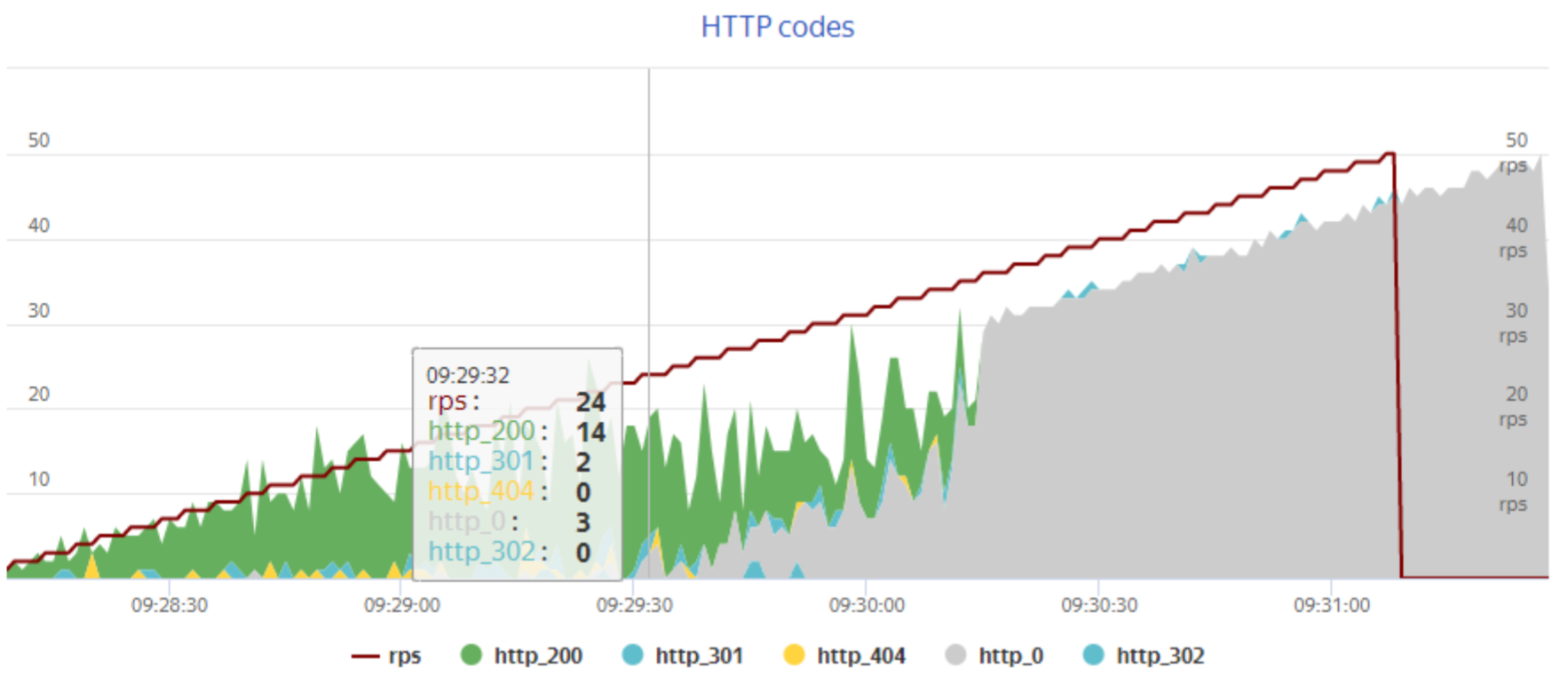
Подобный тест можно сравнить с определением максималки у автомобиля, только здесь мы оперируем RPS (request per second — количество запросов в секунду), а не км/ч. Для сайта таким разгоном может быть, например, запуск рассылки по большой базе адресатов — в этот момент много пользователей одновременно переходят по ссылке и совершают какие-то действия на странице, на которой органический трафик обычно гораздо меньше. Нагрузочный тест позволяет заранее проверить все подобные сценарии.
Результатом теста служат как количественные характеристики (время ответа, скорость работы программного и аппаратного обеспечения, число ошибок и т.д.), так и качественные — есть ли ошибки определенных типов и таймауты, которые показывают, что система не справляется с нагрузкой.
После того, как мы рамочно определили максимальную нагрузку на «быстром» тесте, уточняем её и досконально исследуем поведение системы в предельном состоянии: проводим новые короткие тесты с более высокой точностью, подвергаем инфраструктуру длительным нагрузкам, логируем множество показателей и непосредственно во время тестов анализируем процессы на серверах, ищем слабые звенья и варианты их усиления или замены.
Длинные тесты необходимы, чтобы проверить, как сервис будет работать под продолжительной высокой нагрузкой. Они позволяют найти слабые места, которые не проявляются при кратковременном пиковом воздействии. Если продолжать аналогию с автомобилем, то здесь мы проверяем не разгон, а, например, хотим убедиться, что на скорости 200 км/ч у нас не отвалятся колёса и не перегреется мотор. Для веб-сервиса это, скорее, случай органически возросшей нагрузки, когда пользователей много в течение длительного периода, а не в отдельные моменты времени.
Долговременные нагрузочные тесты ещё называют тестированием стабильности. В нашем контексте IT-инфраструктуры они помогают найти, например, проблемы в коде (неоптимально использование оперативной памяти и как следствие её переполнение); выявить ситуации, когда требуется перезапуск серверов или ПО; проверить, как система отработает рестарт; проверить стабильную работу оборудования (в таком тесте может проявиться банальный перегрев, из-за которого вообще вся система станет не работоспособна).
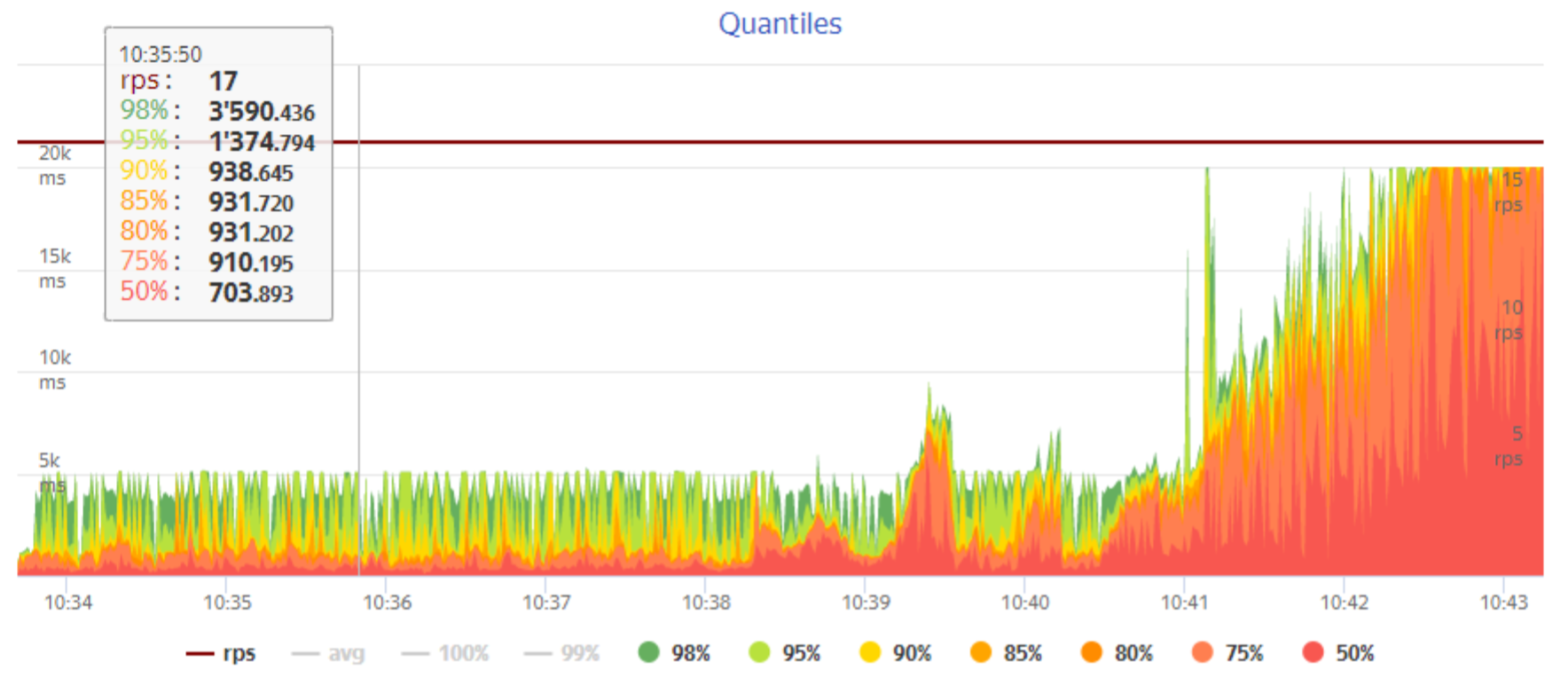
На скриншоте выше пример длительного теста: при заданной нагрузке сайт сначала работает корректно и с приемлемой скоростью, использование памяти, CPU и других элементов инфраструктуры держится на стабильном уровне, но потом некие запросы к базе данных накапливаются и повышают нагрузку на сервер и БД, приводя к проблемам производительности. В процессе теста мы смогли отследить накопившиеся запросы к каталогу и найти причину — и придумали способ изменить запросы, чтобы они работали быстрее и требовали меньше ресурсов. При этом тест получился условно «длинным», хватило примерно 10 минут, чтобы засечь проблемы. В других случаях мы можем нагружать инфраструктуру по несколько часов — то есть продолжительность определяется, исходя из потребностей и результатов. Вообще, нагрузочное тестирование можно провести с любым сетапом — будь то один «железный» сервер или managed Kubernetes в облаке — и проверить именно те узлы, которые важны в данном конкретном случае.
Определение предельной для корректной работы системы нагрузки позволяет проверить стабильность в штатных условиях и, конечно, улучшить её, если результаты не порадовали. Но кроме этого важно тестировать инфраструктуру и при критически высоких, можно сказать, запредельных нагрузках — чтобы знать, какие последствия может вызвать инцидент, сколько времени займёт восстановление нормального состояния и вообще, получится ли восстановить работоспособность сервиса без потери данных. Возвращаясь к автомобильной метафоре — это гонки на выносливость или ралли-рейд Дакар.
И всё-таки: когда всё это нужно?
В идеальном мире тестировать на нагрузки нужно любой развивающийся проект на стадии внесения серьезных обновлений — чтобы быть уверенным, что ничего не поломается и прогнозируемое количество пользователей получат от обновления пользу. В неидеальном и очень конкурентном мире IT бизнесу нужно развиваться, реагировать на среду и менять продукт как можно быстрее, а тестирование, как ни крути, удорожает и замедляет разработку.
Вот две ситуации, когда, на наш взгляд, проводить нагрузочное тестирование необходимо:
-
проект планирует существенно увеличить трафик;
-
есть признаки проблем с нагрузкой в текущей инфраструктуре.
А сценарии, в которых показано нагрузочное тестирование, могут быть такими:
-
Вы готовитесь к бусту: разрабатываете новую функциональность, которая по вашим оценкам должна увеличить количество клиентов, или опять же планируете включить маркетинг на полную мощь.
-
Принимаете проект у подрядчика — хотите убедиться, что он сделан надёжно и выдержит запланированные нагрузки.
-
Вводите в эксплуатацию новую инфраструктуру — нужно определить «запас прочности» до того, как запустить в неё продакшн-трафик.
-
Хотите понять порог и оптимизировать настройки, чтобы текущая инфраструктура работала эффективнее.
-
Накопилось много крупных изменений, которые могут повлиять на быстродействие, — нужно проверить актуальное состояние и найти текущий порог по нагрузке.
Что делать с результатами?
Главным полезным результатом нагрузочного тестирования должно являться:
-
комплексное понимание состояния текущей инфраструктуры;
-
найденные проблемы и способы их устранения для большинства случаев, когда они связаны с конфигурацией (а часто и когда они касаются кода);
-
рекомендации на будущее для большего роста.
Но как известно, лучше один раз увидеть, чем сто раз услышать, так что мы приведём отрывок из реального отчёта.
Итоги тестирования:
1. Исправлены проблемы в конфигурации nginx и «проблема 404».
2. Проведен анализ конфигурации серверного ПО: никаких проблем с настройками MySQL , Apache , nginx не обнаружено — система корректно использует ресурсы.
3. Выявлены текущие пороги системы при тестировании сайта со страницами каталога: X RPS при быстром росте посещаемости, Y RPS при длительно нагрузке. На данный момент имеется приблизительно четырёхкратный запас на рост посещаемости на текущей конфигурации.
Рекомендации:
1. Заменить в запросах каталога
((((BE.CODE LIKE 'stol_leset_tor_kvadratnyy_tsveta_v_assort_'))))
на
((((BE.CODE = 'stol_leset_tor_kvadratnyy_tsveta_v_assort_'))))
— это существенно ускорит данные запросы и позволит снизить нагрузку.
2. Внести изменение в формат таблицы pages_hash для возможности добавления индекса на поле %FIELD_NAME%.
3. Отключать php-расширение xdebug, когда не проводится непосредственный дебаг кода. Использование xdebug влияет на скорость загрузки страниц и потребление ресурсов процессами apache.
«А можно я сам?»
Конечно, можно. Для самостятельного проведения тестирования нужны две вещи: достаточно высокая и разноплановая квалификация штатных инженеров и возможность высвободить для этого 1-2 недели в их рабочем графике. Мы даже подготовили небольшие рекомендации, которые пригодятся вашим айтишникам, если вы всё же решите справиться своими силами. Вот они:
2. Проверьте настройки самого сервера и лимиты sysctl.
3. Проведите первоначальный анализ настроек субд ( например с помощью mysqltuner).
4. Оцените нагрузку на сервере (top atop iftop).
5. Проверьте корректность работы кэшей.
И последнее: стресс для системы — это хорошо, помогает понять пределы её текущих возможностей. Стресс для того, кто владеет системой — ничего хорошего, ведёт лишь к потере времени, денег и нервных клеток. Так что мы вам желаем избежать стресса — проведя нагрузочное тестирование своей информационной системы.