
Мониторинг мёртв? — Да здравствует мониторинг
Я считаю, что в организации правильной системы мониторинга происходит беда. Если бы беды не было, то мой спич состоял из одного тезиса: «Установите, пожалуйста, Prometheus + Grafana и плагины 1, 2, 3». К сожалению, теперь так не работает.
Наша компания с 2008 года занимается преимущественно управлением инфраструктурами и круглосуточной технической поддержкой веб-проектов: у нас более 400 клиентов, это порядка 15% электронной коммерции России. Соответственно, на поддержке очень разнообразная архитектура. Если что-то падает, мы обязаны в течение 15 минут это починить. Но чтобы понять, что авария произошла, нужно мониторить проект и реагировать на инциденты. А как это делать?
Я считаю, что в организации правильной системы мониторинга происходит беда. Если бы беды не было, то мой спич состоял из одного тезиса: «Установите, пожалуйста, Prometheus + Grafana и плагины 1, 2, 3». К сожалению, теперь так не работает. И главная проблема заключается в том, что все продолжают верить во что-то такое, что существовало в 2008 году, с точки зрения программных компонентов.
В отношении организации системы мониторинга я рискну сказать, что… проектов с грамотным мониторингом не существует. И ситуация настолько плохая, если что-то упадёт, есть риск, что это останется незамеченным — все ведь уверены, что «всё мониторится».
Возможно, всё мониторится. Но как?
Все мы сталкивались с историей наподобие следующей: работает некий девопс, некий админ, к ним приходит команда разработчиков и говорит — «мы зарелизились, теперь замониторь». Что замониторь? Как это работает?
Ок. Мониторим по старинке. А оно уже изменяется, и выясняется, что ты мониторил сервис А, который стал сервисом B, который взаимодействует с сервисом C. Но команда разработчиков тебе говорит: «Поставь софт, он же должен все замониторить!»
Так что изменилось? — Всё изменилось!
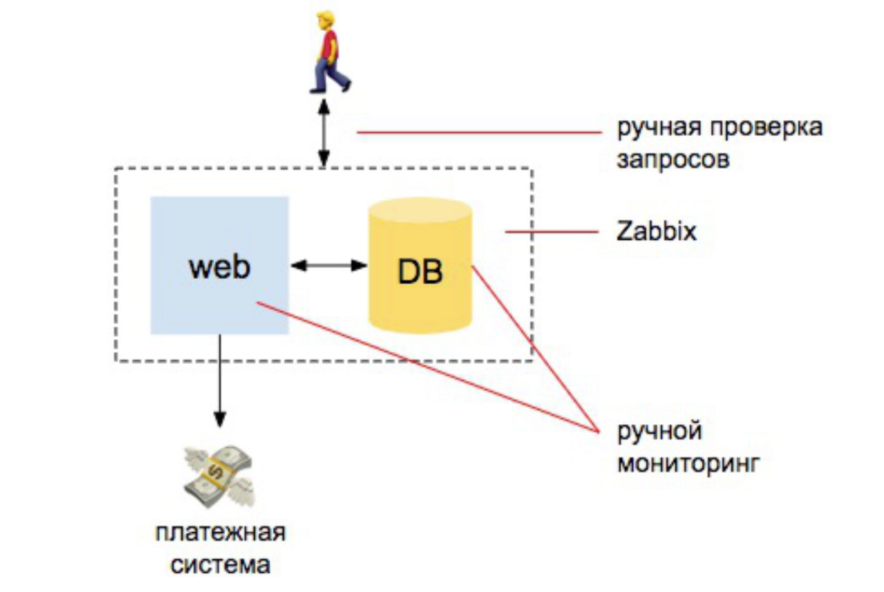
2008 год. Всё прекрасно
Есть пара разработчиков, один сервер, один сервер БД. Отсюда всё и идет. У нас есть некая инфа, мы ставим zabbix, Nagios, cacti. И дальше выставляем понятные алерты на ЦПУ, на работу дисков, на место на дисках. Ещё делаем пару ручных проверок, что сайт отвечает, что заказы в базу приходят. И всё – мы более-менее защищены.
Если сравнивать объем работы, которую тогда делал админ для обеспечения мониторинга, то на 98% она была автоматической: человек, который занимается мониторингом, должен понять, как поставить Zabbix, как его настроить и настроить алерты. И 2% — на внешние проверки: что сайт отвечает и делает запрос в базу, что новые заказы пришли.
2010 год. Растёт нагрузка
Мы начинаем скейлить вебы, добавляем поисковый движок. Мы хотим быть уверены, что каталог товаров содержит все товары. И что поиск товаров работает. Что база работает, что заказы делаются, что сайт отвечает внешне и отвечает с двух серверов и пользователя не выкидывает с сайта, пока он перебалансируется на другой сервер, и т.д. Сущностей становится больше.
Причем сущность, связанная с инфраструктурой, по-прежнему остается самой большой в голове менеджера. По-прежнему в голове сидит идея, что человек, занимающийся мониторингом, — это человек, который поставит zabbix и сможет его конфигурировать.
Но при этом появляются работы по проведению внешних проверок, по созданию набора скриптов запросов индексатора поиска, набора скриптов для проверки того, что поиск меняется в процессе индексации, набора скриптов, которые проверяют, что службе доставке передаются товары, и т.д. и т.п.
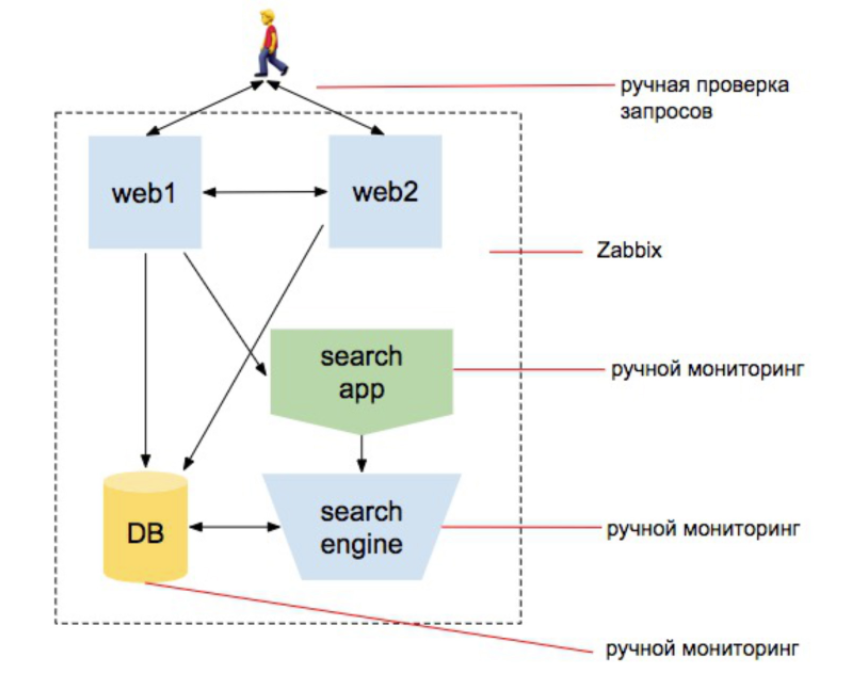
Заметьте: я 3 раза написал «набор скриптов». То есть ответственный за мониторинг — больше не тот, кто просто устанавливает zabbix. Это человек, который начинает кодить. Но в головах у команды пока ничего не меняется.
Зато меняется мир, усложняясь всё больше. Добавляются слой виртуализации, несколько новых систем. Они начинают взаимодействовать между собой. Кто сказал «попахивает микросервисами?» Но каждый сервис всё ещё по отдельности выглядит как сайт. Мы можем к нему обратиться и понять, что он выдаёт необходимую информацию и сам по себе работает. И если ты админ, постоянно занимающийся проектом, который развивается 5-7-10 лет, у тебя эти знания накапливаются: появляется новый уровень — ты его осознал, появляется еще один уровень — ты его осознал…
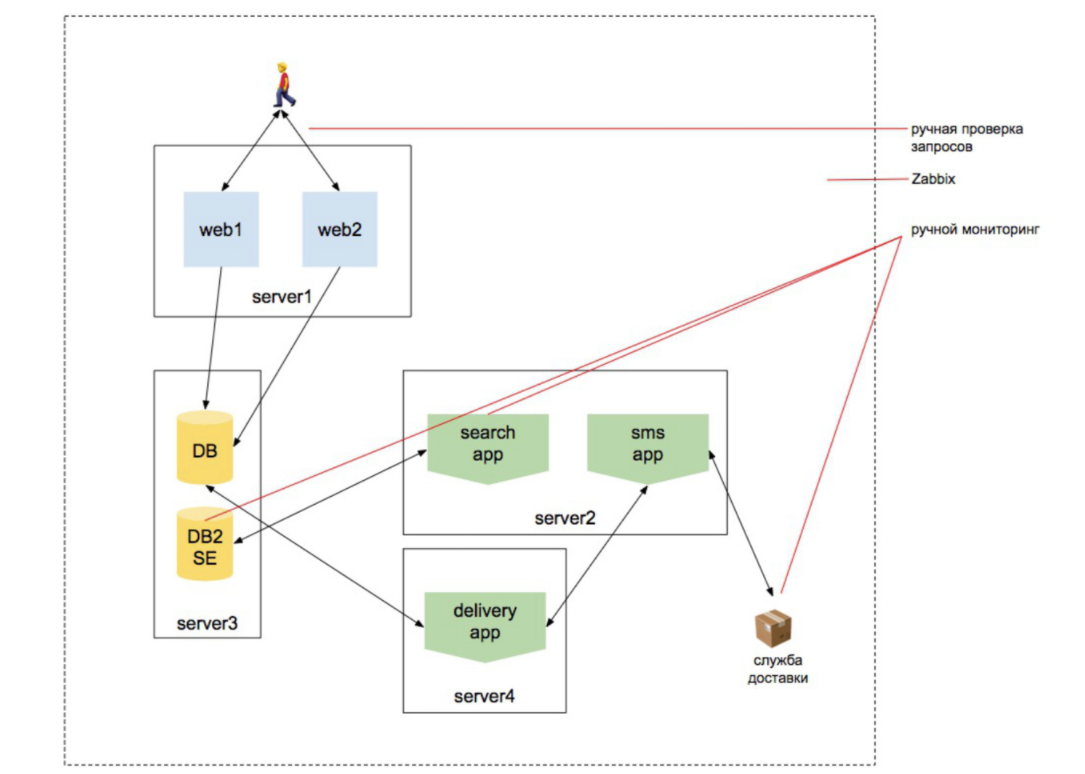
Но редко кто сопровождает проект 10 лет.
Резюме мониторингмэна
Предположим, вы пришли в новый стартап, который сразу набрал 20 разработчиков, написал 15 микросервисов, а вы — админ, которому говорят: «Построй CI/CD. Пожаааалуйста». Вы построили CI/CD и вдруг слышите: «Нам сложно работать с продакшном в «кубике», не понимая, как в нём будет работать приложение. Сделай нам песочницу в этом же «кубике».
Вы делаете песочницу в этом кубике. Вам тут же говорят: «Мы хотим stage базу данных, которая обновляется каждый день с продакшна, чтобы понимать, что это работает на базе данных, но при этом не испортить продакшн базу данных».
Вы в этом всем живете. Остается 2 недели до релиза, вам говорят: «Теперь бы это всё замониторить…» Т.е. замониторить кластерную инфраструктуру, замониторить микросервисную архитектуру, замониторить работу с внешними сервисами…
А коллеги достают такие из головы привычную схему и говорят: «Так здесь же всё понятно! Поставь программу, которая это все замониторит». Да-да: Prometheus + Grafana + плагины.
И добавляют при этом: «У тебя недельки две, сделай так, чтобы все было надёжно».
В куче проектов, которые мы видим, на мониторинг выделяют одного человека. Представьте, что мы хотим на 2 недели нанять человека, который займется мониторингом, и мы составляем ему резюме. Какими навыками должен обладать этот человек — если учитывать все сказанное нами прежде?
- Он должен понимать мониторинг и специфику работы железной инфраструктуры.
- Он должен понимать специфику мониторинга Kubernetes(а все хотят в «кубик», потому что можно абстрагироваться от всего, спрятаться, ведь с остальным разберется админ) — самого по себе, его инфраструктуры, и понимать, как мониторить приложения внутри.
- Он должен понимать, что сервисы между собой общаются особыми способами, и знать специфики взаимодействия сервисов между собой. Вполне реально увидеть проект, где часть сервисов общаются синхронно, потому что по-другому никак. Например, backend идет по REST, по gRPC к сервису каталога, получает список товаров и возвращает обратно. Здесь нельзя ждать. А с другими сервисами он работает асинхронно. Передать заказ в службу доставки, отправить письмо и т.п.
Вы, наверное, уже поплыли от всего этого? А админ, которому нужно это мониторить, поплыл еще больше. - Он должен уметь планировать и планировать правильно — поскольку работы становится всё больше и больше.
- Он должен, следовательно, создать стратегию из созданного сервиса чтобы понять, как это конкретно замониторить. Ему нужно понимание архитектуры проекта и его развития + понимание технологий, использующихся в разработке.
Вспомним абсолютно нормальный кейс: часть сервисов на php, часть сервисов на Go, часть сервисов на JS. Они как-то между собой работают. Отсюда и взялся термин «микросервис»: отдельных систем стало так много, что разработчики не могут понять проект в целом. Одна часть команды пишет сервисы на JS, которые работают сами по себе и не знают, как работает остальная система. Другая часть пишет сервисы на Python и не лезет в то, как работают другие сервисы, они изолированы в своей области. Третья — пишет сервисы на php или чем-то еще.
Все эти 20 человек разделены на 15 сервисов, и есть лишь один админ, который должен всё это понять. Стоп! мы только что разбили систему на 15 микросервисов, потому что 20 человек всю систему понять не могут.
Зато её надо как-то замониторить…
Что в итоге? В итоге есть один человек, которому в голову входит всё, что не может понять целая команда разработчиков, и при этом он ещё должен знать и уметь то, что мы указали выше — железную инфраструктуру, инфраструктуру Kubernetes и т.д.
Что тут сказать… Хьюстон, у нас проблемы.
Мониторинг современного программного проекта — это сам по себе программный проект
Из ложной уверенности, что мониторинг — это софт, у нас появляется вера в чудеса. А чудес, увы, не бывает. Нельзя поставить zabbix и ждать, что всё заработает. Нет смысла поставить Grafana и надеяться, что все будет ок. Большая часть времени уйдет на организацию проверок работы сервисов и их взаимодействия между собой, проверок, как работают внешние системы. Фактически 90% времени уйдет не на написание скриптов, а на разработку программного обеспечения. И заниматься ею должна команда, которая понимает работу проекта.
Если в этой ситуации одного человека кинуть на мониторинг, то случится беда. Что и происходит повсеместно.
Например, есть несколько сервисов, которые общаются между собой через Kafka. Пришел заказ, мы сообщение о заказе отправили в Kafka. Есть сервис, который слушает информацию о заказе и проводит отгрузку товара. Есть сервис, который слушает информацию о заказе и присылает письмо юзеру. А затем появляется еще куча сервисов, и мы начинаем путаться.
А если вы ещё отдадите это админу и разработчикам на этапе, когда до релиза осталось короткое время, человеку нужно будет понять весь этот протокол. Т.е. проект подобного масштаба занимает значительное время, и в разработке системы это должно быть заложено.
Но очень часто, особенно в горении, в стартапах, мы видим, как мониторинг откладывают на потом. «Сейчас мы сделаем Proof of Concept, с ним запустимся, пусть он падает – мы готовы жертвовать. А потом мы все это замониторим». Когда (или если) проект начинает приносить деньги, бизнес хочет пилить ещё больше фич — потому что оно же начало работать, значит нужно накручивать дальше! А вы находитесь в точке, где вначале нужно замониторить всё предыдущее, что занимает не 1% времени, а значительно больше. И кстати для мониторинга нужны будут разработчики, а их проще пустить на новые фичи. В итоге пишутся новые фичи, всё накручивается, и вы в бесконечном deadlock.
Так как же замониторить проект, начиная с начала, и что делать, если вам достался проект, который нужно замониторить, а вы не знаете, с чего начинать?
Во-первых, нужно планировать.
Лирическое отступление: очень часто начинают с мониторинга инфраструктуры. Например, у нас Kubernetes. Начнем с того, что поставим Prometheus с Grafana, поставим плагины под мониторинг «кубика». Не только у разрабов, но и у админов есть прискорбная практика: «Мы поставим вот этот плагин, а плагин наверное знает как это сделать». Люди любят начинать с простых и понятных, а не с важных действий. И мониторинг инфраструктуры — это просто.
Для начала решите, что и как хотите замониторить, а потом подбирайте инструмент, потому что другие люди не могут за вас подумать. Да и должны ли? Другие люди думали про себя, про универсальную систему — или вообще не думали, когда этот плагин писали. И то, что у этого плагина 5 тысяч пользователей, не означает, что он несёт какую-то пользу. Возможно, вы станете 5001-ым просто потому, что там до этого уже было 5000 человек.
Если вы начали мониторить инфраструктуру и backend вашего приложения перестал отвечать, все пользователи потеряют связь с мобильным приложением. Вылетит ошибочка. К вам придут и скажут «Приложение не работает, чем вы тут занимаетесь?» — «Мы мониторим». — «Как вы мониторите, если не видите, что приложение не работает?!»
- Я считаю, что начинать мониторить нужно именно с точки входа пользователя. Если юзер не видит, что приложение работает — всё, это провал. И система мониторинга должна предупредить об этом в первую очередь.
- И только потом мы можем замониторить инфраструктуру. Или сделать это параллельно. С инфраструктурой проще — тут мы, наконец-то, можем просто поставить zabbix.
- И теперь нужно идти в корни приложения, чтобы понять, где что не работает.
Главная моя мысль – мониторинг должен идти параллельно с процессом разработки. Если вы оторвали команду мониторинга на другие задачи (создание CI/CD, песочницы, реорганизацию инфраструктуры), мониторинг начнет отставать и вы, возможно, уже никогда не догоните разработку (либо рано или поздно придется её остановить).
Всё по уровням
Вот как я вижу организацию системы мониторинга.
1) Уровень приложения:
- мониторинг бизнес-логики приложения;
- мониторинг health-метрики сервисов;
- интеграционный мониторинг.
2) Уровень инфраструктуры:
- мониторинг уровня оркестрации;
- мониторинг системного ПО;
- мониторинг уровня «железа».
3) Вновь уровень приложения — но уже как инженерного продукта:
- сбор и наблюдение журналов приложения;
- APM;
- tracing.
4) Алертинг:
- организация системы оповещения;
- организация системы дежурств;
- организация «базы знаний» и workflow обработки инцидентов.
Важно: мы доходим до алертинга не после, а сразу! Не надо запускать мониторинг и «как-нибудь потом» придумывать, кому будут приходить алерты. Ведь в чём задача мониторинга: понять, где в системе что-то работает не так, и дать об этом знать нужным людям. Если это оставить на конец, то нужные люди узнают о том, что что-то идет не так, только по звонку «у нас ничто не работает».
Уровень приложения — мониторинг бизнес-логики
Здесь речь идет о проверках самого факта того, что приложение работает для пользователя.
Этот уровень должен быть сделан на этапе разработки. Например, у нас есть условный Prometheus: он лезет к серверу, который занимается проверками, дёргает endpoint, и endpoint идет и проверяет API.
Когда часто просят замониторить главную страницу чтобы убедиться, что сайт работает, программисты дают ручку, которую можно дёргать каждый раз, когда надо убедиться, что API работает. А программисты в этот момент еще берут и пишут /api/test/helloworld
Единственный способ убедиться, что все работает? — Нет!
- Создание таких проверок — по сути, задача разработчиков. Unit-тесты должны писать программисты, которые пишут код. Потому что, если вы сольете это на админа «Чувак, вот тебе список протоколов API всех 25 функций, пожалуйста, замониторь все!» — ничего не получится.
- Если вы сделаете print “hello world”, никто не узнает никогда о том, что API должен и действительно работает. Каждое изменение API должно вести за собой изменение проверок.
- Если у вас уже такая беда – остановите фичи и выделите разработчиков, которые напишут эти проверки, либо смиритесь с потерями, смиритесь, что ничего не проверяется и будет падать.
Технические советы:
- Обязательно организуйте внешний сервер для организации проверок — вы должны быть уверены, что ваш проект доступен для внешнего мира.
- Организуйте проверку по всему протоколу API, а не только по отдельным endpoint-ам.
- Создайте prometheus-endpoint с результатами проверок.
Уровень приложения — мониторинг health-метрик
Теперь речь идет о внешних health-метриках сервисов.
Мы решили, что все “ручки” приложения мониторим с помощью внешних проверок, которые мы вызываем из внешней системы мониторинга. Но это именно “ручки”, которые “видит” пользователь. Мы же хотим быть уверены, что у нас работают сами сервисы. Здесь история получше: в K8s есть health-чеки, чтобы хотя бы сам «кубик» убеждался, что сервис работает. Но половина чеков, которые я видел, — это тот же самый print “hello world”. Т.е. вот он дергает один раз после деплоя, ему тот ответил, что все хорошо — и всё. А у сервиса, если он rest-ом выдает свой API, есть огромное количество точек входа того самого API, который тоже нужно мониторить, потому что мы хотим знать, что он работает. И мы его мониторим уже внутри.
Как это правильно реализовать технически: каждый сервис выставляет endpoint о своей текущей работоспособности, а в графиках Grafana (или любого другого приложения) мы видим статус всех сервисов.
- Каждое изменение API должно вести за собой изменение проверок.
- Новый сервис создавайте сразу c health-метриками.
- Админ может прийти к разработчикам и попросить «допишите мне пару фич, чтобы я всё понимал и в свою систему мониторинга добавил информацию об этом». Но разработчики обычно отвечают «За две недели до релиза мы ничего дописывать не будем».
Пусть менеджеры разработки знают, что будут такие потери, пусть начальство менеджеров разработки тоже знает. Потому что, когда все упадет, кто-то все равно позвонит и потребует замониторить «постоянно-падающий сервис» (с) - Кстати, выделите разработчиков на написание плагинов для Grafana— это будет хорошая помощь для админов.
Уровень приложения — Интеграционный мониторинг
Интеграционный мониторинг фокусируется на мониторинге коммуникации между критическими для бизнеса системами.
Например, есть 15 сервисов, которые коммуницируют между собой. Это больше не отдельные сайты. Т.е. мы не можем дернуть сервис сам по себе, получить /helloworld и понять, что сервис работает. Потому что веб-сервис оформления заказа должен отправить информацию о заказе в шину — из шины служба работы со складом должна получить это сообщение и работать с ним дальше. А служба рассылки e-mail-ов должна обработать это как-то дальше, и т.д.
Соответственно, мы не можем понять, тыкаясь в каждый отдельный сервис, что это все работает. Потому что у нас есть некая шина, через которую все общается и взаимодействует.
Поэтому этот этап должен обозначать собой этап тестирования сервисов по взаимодействию с другими сервисами. Нельзя, замониторив брокер сообщений, организовать мониторинг коммуникации. Если есть сервис, который выдает данные, и сервис, который их принимает, при мониторинге брокера мы увидим только данные, которые летают из стороны в сторону. Если даже мы как-то умудрились замониторить взаимодействие этих данных внутри — что некий продюсер постит данные, кто-то их читает, этот поток продолжает идти в Kafka— это всё равно не даст нам информацию, если один сервис отдал сообщение в одной версии, а другой сервис не ожидал этой версии и пропустил его. Мы об этом не узнаем, так как нам сервисы скажут, что все работает.
Как я рекомендую делать:
- Для синхронной коммуникации: endpoint выполняет запросы к связанным сервисам. Т.е. мы берем этот endpoint, дергаем скриптик внутри сервиса, который идёт по всем точкам и говорит «я могу там дернуть, и там дернуть, могу там дернуть…»
- Для асинхронной коммуникации: входящие сообщения — endpoint проверяет шину на наличие тестовых сообщений и выдает статус обработки.
- Для асинхронной коммуникации: исходящие сообщения — endpoint отправляет на шину тестовые сообщения.
Как обычно происходит: у нас есть сервис, который кидает данные в шину. Мы приходим в этот сервис и просим рассказать о его интеграционном здоровье. И если сервис должен запродьюсить какое-то сообщение куда-то дальше (WebApp), то он это тестовое сообщение продьюсит. А если мы дергаем сервис на стороне OrderProcessing, он сначала постит то, что он может запостить независимое, а если есть какие-то зависимые штуки — то он читает из шины набор тестовых сообщений, понимает, что он может обработать их, сообщить об этом и, если надо, постить их дальше, и про это он говорит — всё ок, я живой.
Очень часто мы слышим вопрос “как мы можем это тестировать на боевых данных?” Например, речь идет про ту же службу заказов. Заказ отправляет сообщения в склад, где списываются товары: мы же не можем протестировать это на боевых данных, потому что «у меня товары будут списываться!» Выход: на начальном этапе запланировать весь этот тест. У вас же есть unit-тесты, которые делают mock-и. Так вот, сделайте это на более глубоком уровне, где у вас будет проходить канал коммуникации, который не повредит работе бизнеса.
Уровень инфраструктуры
Мониторинг инфраструктуры – то, что давно считается самим мониторингом.
- Мониторинг инфраструктуры можно и нужно запустить как отдельный процесс.
- Не стоит начинать с мониторинга инфраструктуры на работающем проекте, даже если очень хочется. Это болячка для всех девопсов. «Сначала замониторю кластер, замониторю инфраструктуру» – т.е. сначала замониторит то, что лежит внизу, а в приложение не полезет. Потому что приложение — непонятная штука для девопса. Ему это слили, и он не понимает, как это работает. А инфраструктуру он понимает и начинает с нее. Но нет — всегда вначале нужно мониторить приложение.
- Не переборщите с количеством оповещений. Учитывая сложность современных систем, алерты летят постоянно, и с этой кучей алертов надо как-то жить. И человек on-call, посмотрев на сотню очередных алертов, решит «не хочу об этом думать». Алерты должны оповещать только о критичных вещах.
Уровень приложения как бизнес-единицы
Ключевые моменты:
- ELK. Это индустриальный стандарт. Если по какой-то причине вы не агрегируете логи, срочно начните это делать.
- APM. Внешние APM как способ быстро закрыть мониторинг приложения (NewRelic, BlackFire, Datadog). Вы можете временно поставить эту штуку, чтобы хоть как-то понять, что у вас происходит.
- Tracing. В десятках микросервисов вы должны трейсить всё, потому что запрос уже не живет сам по себе. Дописать позже очень сложно, поэтому лучше сразу запланировать tracing в разработке — это работа и утилита разработчиков. Если ещё не внедрили – внедряйте! См. Jaeger/Zipkin
Алертинг
- Организация системы оповещений: в условиях мониторинга кучи вещей должна быть единая система рассылки оповещений. Можно в Grafana. На Западе все используют PagerDuty. Оповещения должны быть понятными (например, откуда они пришли…). И желательно контролировать, что оповещения вообще доходят
- Организация системы дежурств: алерты не должны приходить всем (либо будут все толпой реагировать, либо никто не будет реагировать). Oncall нужно быть и разработчикам: обязательно определите зоны ответственности, сделайте четкую инструкцию и пропишите в ней, кому конкретно звонить в понедельник и среду, а кому — во вторник и пятницу (иначе не будут никому звонить даже в случае большой беды — побоятся разбудить, потревожить: люди вообще не любят звонить и будить других людей, особенно ночью). И объясните, что обращение за помощью — не показатель некомпетентности («я прошу помощи — значит я плохой работник»), поощряйте просьбы о помощи.
- Организация «базы знаний» и workflow обработки инцидентов: по каждому серьёзному инциденту должен быть запланирован постмортем, в качестве временной меры должны быть зафиксированы действия, которые решат инцидент. И заведите практику, что повторяющиеся алерты — это грех; их надо фиксить в коде или инфраструктурных работах.
Технологический стек
Давайте представим, что стек у нас следующий:
- сбор данных — Prometheus + Grafana;
- анализ логов — ELK;
- для APM или Tracing — Jaeger (Zipkin).
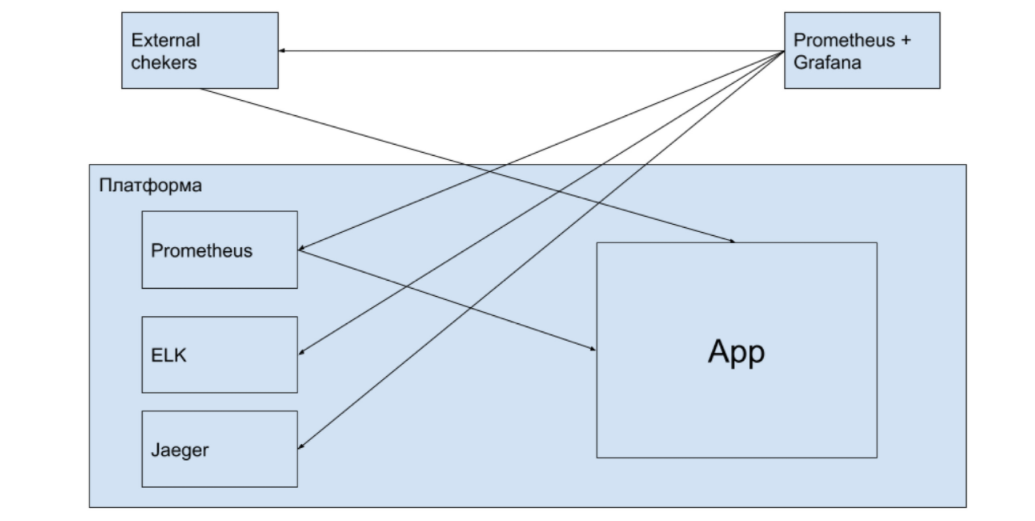 Выбор вариантов некритичен. Потому что, если вы в начале поняли, как замониторить систему и расписали план, дальше вы уже начинаете выбирать инструментарий под свои требования. Вопрос в том, что вы выбрали мониторить вначале. Потому что, возможно, инструмент, который вы выбрали вначале — он вообще не подходит под ваши требования.
Выбор вариантов некритичен. Потому что, если вы в начале поняли, как замониторить систему и расписали план, дальше вы уже начинаете выбирать инструментарий под свои требования. Вопрос в том, что вы выбрали мониторить вначале. Потому что, возможно, инструмент, который вы выбрали вначале — он вообще не подходит под ваши требования.
Несколько технических моментов, которые я вижу везде в последнее время:
Prometheus пихают внутрь Kubernetes — кто это придумал?! Если у вас упадет кластер, что вы будете делать? Если у вас сложный кластер внутри, то должна работать некая система мониторинга внутри кластера, и некая — снаружи, которая будет собирать данные изнутри кластера.
Внутри кластера мы собираем логи и все остальное. Но система мониторинга должны быть снаружи. Очень часто в кластере, где есть Promtheus, который поставили внутрь, там же стоят системы, которые делают внешние проверки работы сайта. А если у вас соединения во внешний мир упали и приложение не работает? Получается, внутри у вас все хорошо, но пользователям от этого не легче.
Выводы
- Разработка мониторинга — не установка утилит, а разработка программного продукта. 98% сегодняшнего мониторинга — это кодинг. Кодинг в сервисах, кодинг внешних проверок, проверки внешних сервисов, и всего-всего-всего.
- Не жалейте времени разработчиков на мониторинг: это может занять до 30% их работы, но стоит того.
- Девопсы, не переживайте, что у вас не получается что-то замониторить, потому что некоторые вещи — это вообще другой склад ума. Вы не были программистом, а работа мониторинга — именно их работа.
- Если проект уже работает и не замониторен (а вы менеджер) — выделите ресурсы на мониторинг.
- Если продукт уже в продакшне, а вы девопс, которому сказали «настроить мониторинг» — попытайтесь объяснить руководству то, о чем я всё это написал.
Это расширенная версия доклада на конференции Saint Highload++.
UPD (по итогам обсуждения этого поста):
1. Может показаться, что целью статьи, среди прочего, является тезис «админы, не парьтесь, мониторинг не ваша забота, пусть программисты мучаются». Разумеется, это не так: как DevOps объединил программистов и админов, так и цель статьи — как раз показать, что, прежде всего, совместная работа.
2. Я не пытаюсь намекнуть, мол «везде все плохо, а вот мы сможем сделать вам мониторинг — приходите в ITSumma». Нет, если проект запущен — мониторинг сторонней компанией не сделать. Конечно, у нас есть и бизнес-цели, и что мы действительно думаем сделать, так это внедрить консалтинг по сопровождению проекта в процессе его разработки, чтобы донести, как правильно со стороны разработки вести часть, связанную с мониторингом.


















